

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)

Resilience engineering and the need to have a Center of Excellence (CoE) for it.
There was a time when the success of software application engineering was measured by whether the team delivered a solution within the stipulated time and budget. But now, that is no longer enough.
Today, engineers are expected to deliver round-the-clock working solutions that offer consistent user experience and add to business value. Thus, building reliable and resilient systems has become a dire need of the hour for businesses.
Resilience engineering is building resilience in a system to recover faster from unexpected conditions where the user experience remains uninterrupted while providing an acceptable service level to the business. Resilient systems can handle a massive scale of online transactions reliably while delivering a consistent user experience.
Before we deep dive into the significance of resilience engineering, let us start with a few questions:

In a nutshell, you need to begin your resiliency journey because: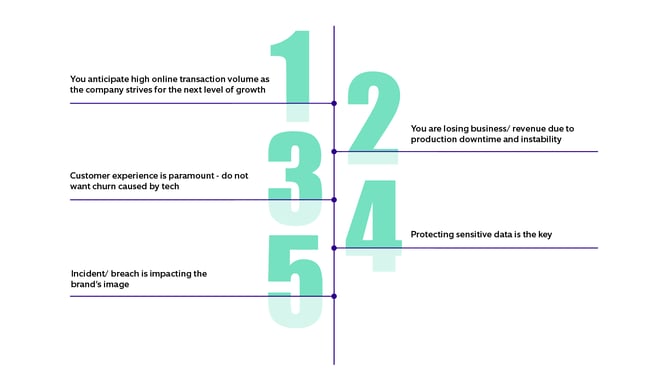
In this scenario, to fully leverage the potential of resilience engineering, A Center of Excellence (CoE), or a competency or capability center, can prove pivotal to any organization that wants to realize digital transformation across its business. A CoE is an organization’s dedicated and specialized hub that focuses on developing and promoting resilience practices and principles.
In this blog, we will share how our expertise in Resilience Engineering helped clients democratize resiliency across their enterprise with a centralized team.
Setting up a CoE for Resilience Engineering
As an organization, you require a CoE for resilience engineering for several reasons, such as establishing standards and best practices, providing thought leadership and direction, research and development, exploring and adopting the right technology tools and techniques, and empowering the organization with business insights. When it comes to the role of a CoE for resilience engineering, the competency center will be focused on:
- Resiliency consulting: Determining the current state via assessments, preparing roadmaps and defining architecture to achieve high reliability and resiliency.
- Resiliency engineering, support, and scalability: Framework development to scale resiliency efforts across the organization. We are also focusing on the security and performance of systems.
- Training and onboarding: Identifying resiliency champions, creating a framework to bring teams up-to-speed about tools, technology standards, and best practices, and designing engineering training pathways.
Now, let’s discuss in detail how we helped our client establish a CoE to drive resilience engineering across the organization by following these steps:
- Start with having a well-defined vision
- Define the CoE’s scope and services
- Create a framework/roadmap
- Build the team
- Ensure governance
Step one: Start with a well-defined vision
While resilience engineering helps businesses reduce the impact of any sudden disruption in the system, resiliency goals can vary for businesses for the system that is to be made resilient. Our customers found it difficult to articulate their vision and determine where to begin their journey. For example, objectives can vary from ‘ensuring less downtime’ to ‘ensuring the software can reliably withstand 2000+ concurrent transactions without any impact on user experience’.
So, we start by clearly outlining the objectives you wish to achieve and the purpose of setting up the CoE, which is majorly building the center as an enabler for other departments to adopt resilience engineering. This step entails having a basic understanding of your applications and services that are to be made resilient. For instance, SaaS organizations typically have an SLA to meet 99.95% uptime each month. If they fail to meet the SLA, chargeback clauses are defined accordingly.
Our focus is also on achieving the objectives proactively in a bid to prevent incidents rather than merely reacting to them. Reliability programs entail adopting a long-term, policy-driven approach to attain the desired reliability levels.
Step two: Define the CoE’s Scope and Services
In the next step, we define the scope of the CoE and its services, for instance, bringing topics like performance, security, and reliability under the umbrella of resilience engineering. Depending upon the scope, we include different enablers contributing to overall resiliency and incubating skills.
As far as the roles and functions of the Resilience Engineering CoE team are concerned, they are centered around the following:
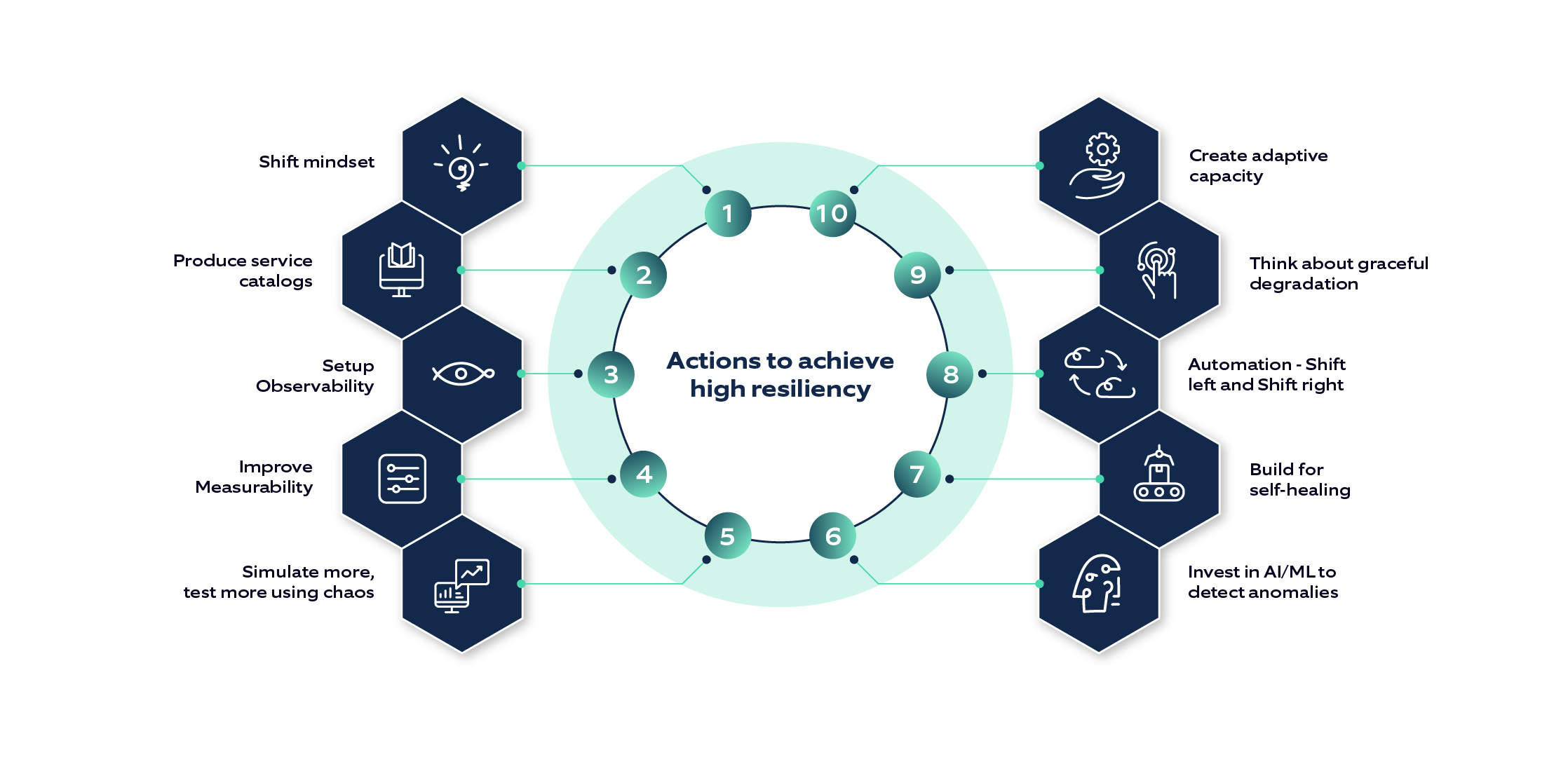
To further enhance the scope of the CoE, we recommend adding performance and security engineers to the team who can identify and build scenarios to further help build the PoV about software resilience.
We have worked on building a foundation platform providing the required knowledge of tooling, observability, automation, and resilient software architecture patterns. To monitor the system's performance in the production environment, we built a team of SREs. They help manage incidents efficiently, gain intelligence, and learn from past mistakes to be ready for a better future.
Step three: Create a Roadmap/Framework
Once we have defined the overarching strategy to achieve the set goals, it’s time to build a framework to achieve them.
Nagarro Resilience Engineering Framework (NREF) is a fine example of enabling businesses to scale chaos engineering efforts quickly across the enterprise. We leverage it to build reliable solutions that deliver a consistent experience. This ensures massive transactions can be carried out in a day with high system availability/up-time of up to four or five 9s.
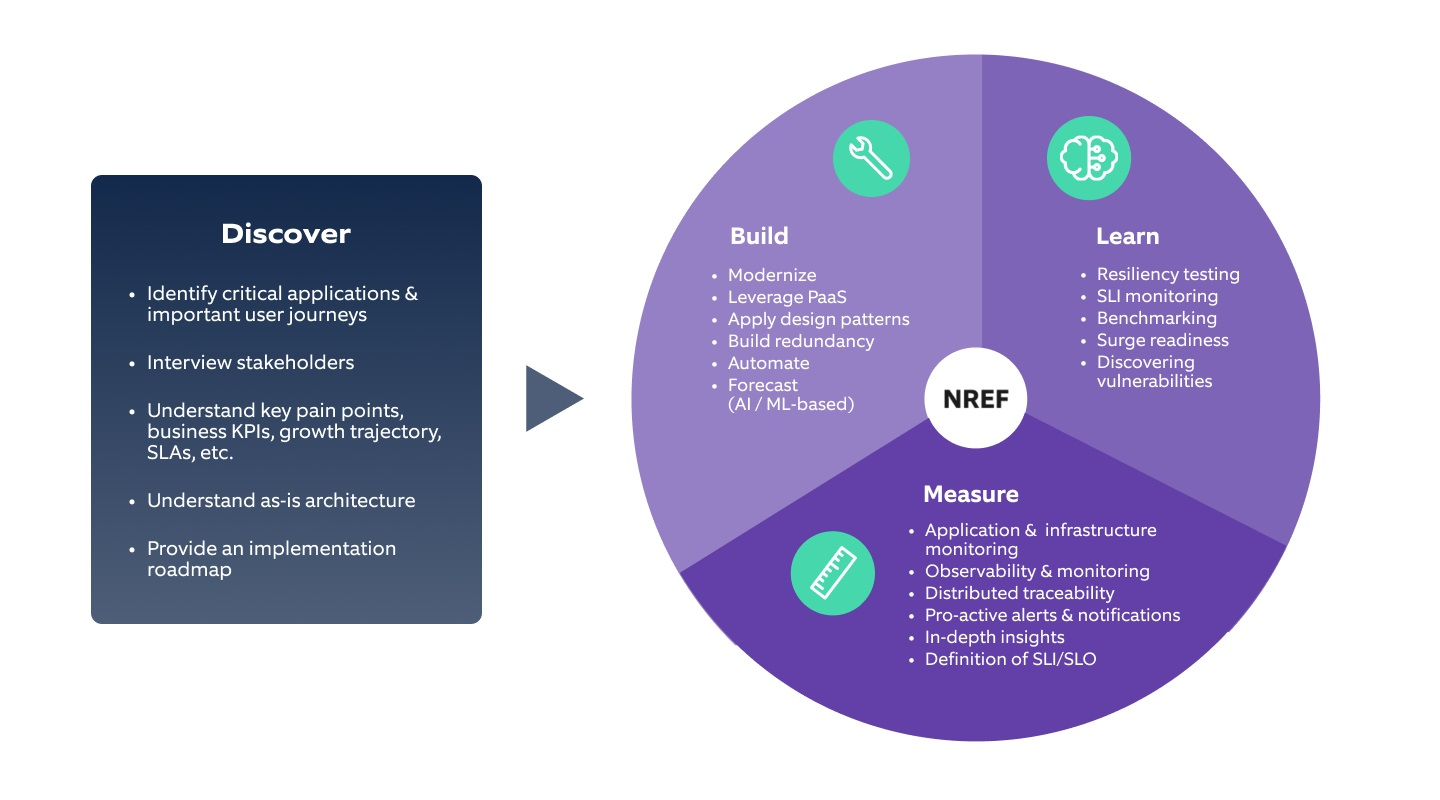
As a specific example, in situations where banks secure contracts to sell their financial services, there is a spike in website traffic as customers flock banking systems to acquire services such as home loans.
To be able to cater to the requests, we help build system reliability with a focus on increasing the availability of this service so that it is ready to support demand from multiple distribution channels.
So, how do we make the service resilient? Leveraging the framework, we:
- Identify the candidates for resiliency. Candidates can be applications and/or services with high transaction volumes.
- Assess the current state of resiliency and baseline critical indicators like performance, uptime, reliability, and recovery.
- Determine the next best actions aligned with Nagarro’s Resilience Engineering Framework (NREF) to create the roadmap.
- Measure progress via improvements in KPIs.
Step four: Build the team
Once we have built the roadmap, the next critical step is to work on building the team for which there can be different models. Let's explore these models:
- A central CoE team: The core function of this team will be to focus on building tooling, frameworks, and automation that the organization can utilize to achieve its resiliency goals. For example, a central resiliency testing team will share the repeatable resiliency experiments across the application landscape.The same testing team would also be responsible for building scalable frameworks that democratize the usage of these experiments. To help businesses expedite their journey to make their applications resilient and reliable, we have built a ‘Continuous Resiliency Testing Accelerator’ in line with proprietary NREF. It is compatible with all the leading chaos engineering platforms and helps teams execute resiliency testing in every stage of the development cycle.
- Hybrid CoE team: In this model, while there will not be any central team for resilience engineering per se, individual feature teams can decide on having resources to select tools and implement the resilience engineering framework to achieve their resiliency goals. We have seen mature organizations with clarity in resiliency goals adopt this team model. It is an evolution from the central CoE team model, where the central team has built enough frameworks, reusable assets, and clear onboarding guidelines for teams to embrace and implement resiliency engineering concepts independently. This principle can be applied to the human capital management software-as-a-service vertical to help them improve the resiliency of core services at the network and application levels. Following a hybrid CoE team model, we can build a dedicated team to collaborate with different service groups to help reduce the impact of downtime on critical services to less than 30 minutes.
Our ideal team will deliver the following key roles:
- Chaos architect who collaborates with product service owners to design the hypothesis, plan the chaos experiments, and plan & drive Gamedays.
- Cloud architect who collaborates with product service owners to understand the architecture, outages, and impact of downtime on critical components.
- Automation engineers who collaborate with architects to build chaos experiments, develop automation, and make observations.
An automation pipeline can be built that integrates a chaos platform to inject faults to attack the product's services, work with engineering services teams to determine service level indicators and objectives for designing the hypothesis, integrate observability and monitoring tools, conduct Gamedays every sprint while incrementally increasing the blast radius as well as benchmark performance and response time based on production-like load of 250k+ users on critical services. - Co-exist: In this model, there can be a central team retaining the CoE, but at the same time, it injects people into the feature teams to help them achieve their resiliency goals rather than enabling the latter to consume the resiliency framework on their own. Alongside, the key is to come up with the right team structure.
Roles of an ideal team:
- Resiliency Architect: Responsible for validating/verifying the architecture to achieve the overall resiliency goals. Typically, these roles come with a strong enterprise background.
- Resiliency Test Engineer: Their focus is on the performance, security, and resiliency. We have also seen test engineers having an in-depth understanding of cloud infrastructure.
- Observability Engineer: Responsible for monitoring, incident management, and root-cause analysis.
- Automation Engineer: Focus on DevOps and automation.
- Program Manager: Having a deeper understanding of the overall functional ecosystem, how the systems work, and communicating the message about the system functioning amongst all the stakeholders.
A team comprising a Resiliency Architect, a Resiliency Developer, a Resiliency Engineer and an automation engineer should be enabled for the onboarding of new applications and an increase in reliability.
Here’s an example of a CoE collaborating with different groups within an organization:
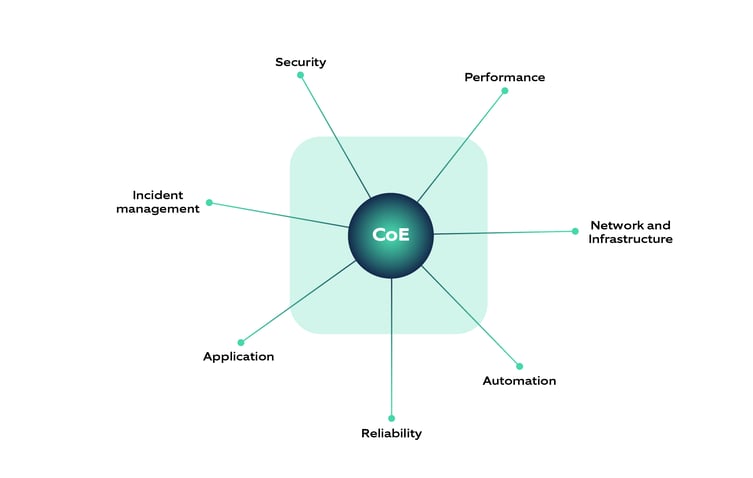
Step five: Ensure Governance
One of the most important aspects of the CoE is to drive continuous monitoring and governance by:
• Performing due diligence to introduce the right resiliency patterns.
• Setting up the right metrics to monitor SLI/SLOs.
• Evaluating how they are testing the resiliency/reliability of an application.
• Deliberating what MTTR they achieve, and how much is it moving with the maturity of the system.
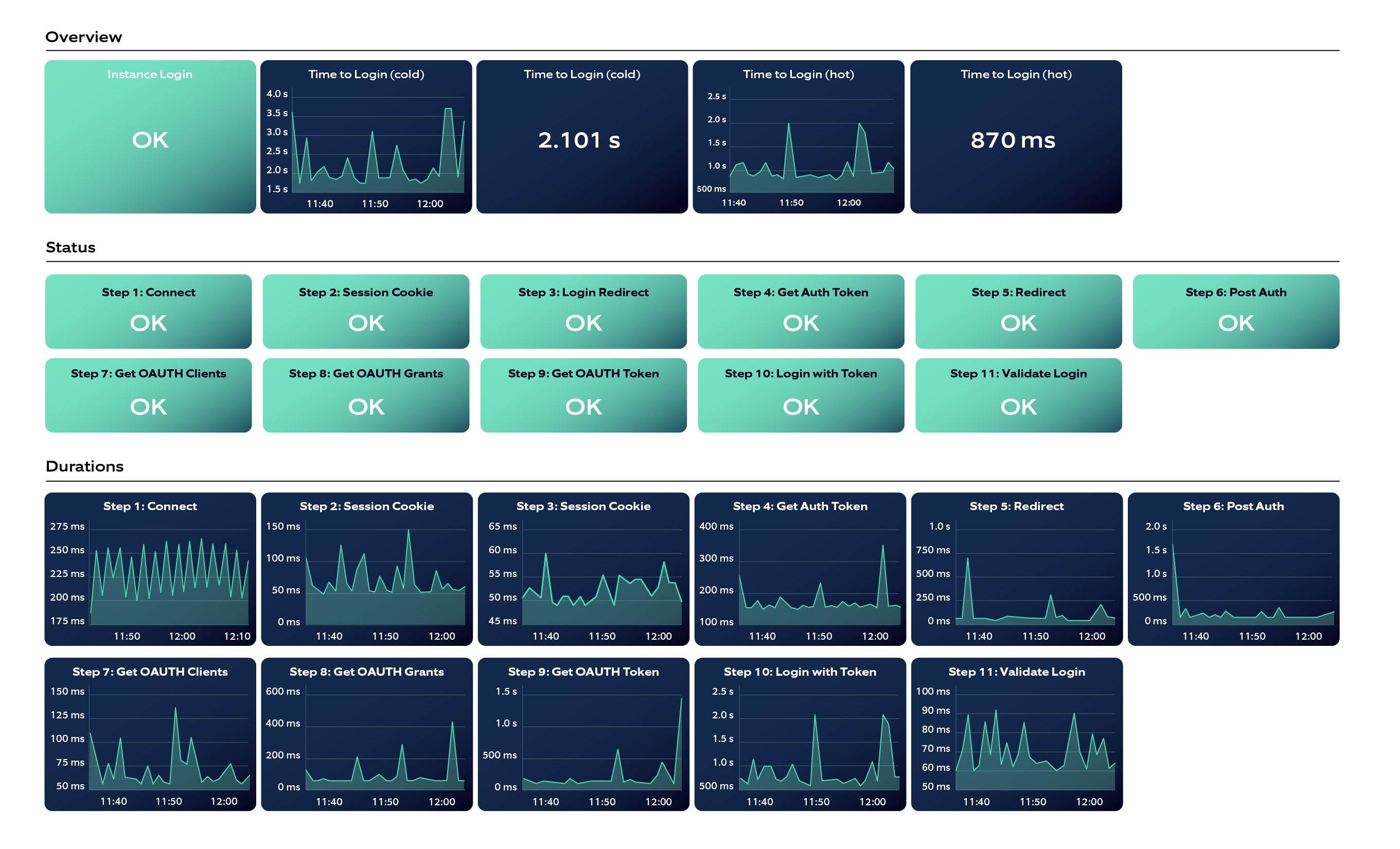
Building a dashboard helps provide an overview of the entire system by grouping charts and visualizations of metrics. Given below is a Grafana custom dashboard that we curated for one of our projects:
In another case, we volunteered and co-founded the first federal digital employment platform for blue and grey-collar workers. We mapped the complete job seeker journey with an intuitive user interface.
Has your software lately been facing outages that are disrupting the user experience? Do you want zero downtime, defects, and failures for all your critical applications? It’s time you set-up a CoE a resilience engineering.
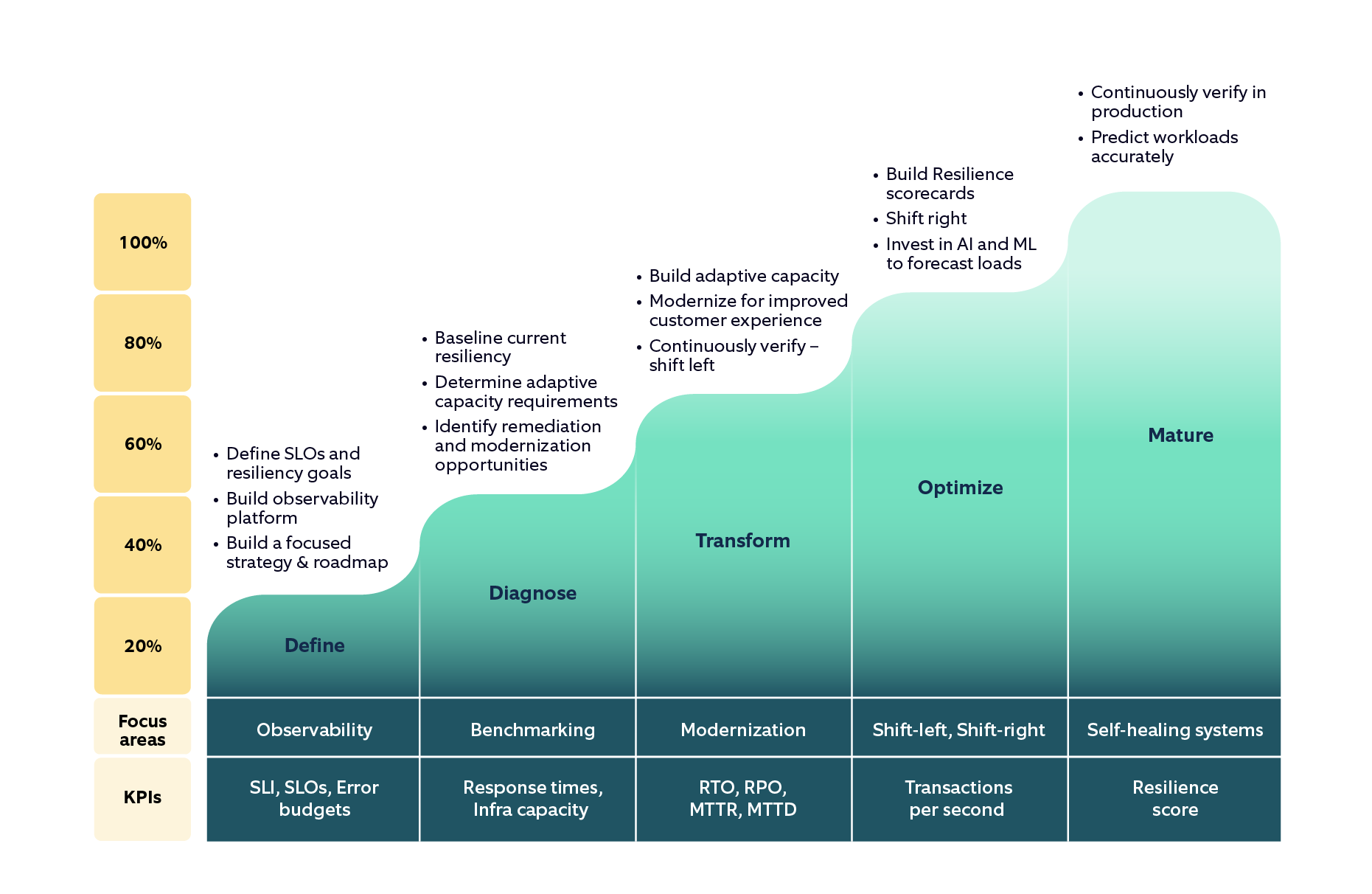
A CoE is also responsible for taking teams through a maturity journey. Nagarro has developed a software resiliency maturity model that helps assess the current state of a system, determine the root cause of a critical incident, become confident about the software’s resilience, and handle billions of online transactions in a day.
Here’s the maturity model to build resilient systems:
How we can help
We understand there is no ‘one size, fits all’ strategy for building a Center of Excellence.
Hence, we help our customers in:
- Setting up observability in Azure App Insights and NewRelic, enabling tracing of critical user journeys
- App modernization - replacing custom code with stable open-source alternatives and modernizing to .NET Core
- Benchmarking critical services, goal setting – defining SLI, SLOs
- Setting up the alerting system Power BI dashboard to track performance, availability.
- Setting up a custom incident management program, DR, automating runbooks & testing in production
The design requirements can vary depending on the organization’s vision, maturity level and goals. With expertise in resilience engineering, we can help you build a CoE that bridges the gap between teams and provides leadership, best practices, research, support, or training on the subject.
Click here to get in touch with us today.

