

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)

With organizations embracing cloud for innovation, the big three commercial Hadoop distributors (MapR, Cloudera, and Hortonworks) have run into financial trouble in recent years. Furthermore, there is a significant change in the mindset of Chief Information Officers (CIOs), and data is now the centrepiece of their roadmap for driving innovations.
This spotlight on data comes with its share of challenges. We need a clear strategy to get data on cloud, with an innovation roadmap. Clients across various industry segments are leveraging big data for a variety of use cases.
Let us discuss a case study:
A healthcare client, having around 200 GB+ of daily data ingestion from multiple sources, wanted to move to the cloud to convert its data platform into a global SaaS (Software as a Service) product. They wanted to use the cloud data platform as a single source of truth for all their current and future platforms. Data was generated from the legacy systems and devices/sensors (in millions) emitting thousands of data points in a month, from on-premise installations. Apart from integrations with Salesforce CRM, Oracle Warehouse, and other legacy systems, the client also had stringent security and compliance requirements.
Understanding Cloud in the context of big data
After a detailed session with the client, the following primary challenges were identified:
- Legacy Transmod (transformation and modernization): Integrating with the legacy infrastructure/systems is complicated, as the CRM systems were on-premise. Further, no data could be shared without anonymization and meeting compliances.
- Security: Mapping security and compliance to make security an enabler of the client’s business strategies. Besides this, HIPPA, PCI, etc. compliances add to the complexity of the demand.
- Vendor lock-ins: Avoiding the selection of proprietary systems so that vendor locking could be averted.
- Costs: Optimizing the costs, as the volume of big data is always huge, and long-term costs were a concern.
Implementing our technology roadmap
Step 1: Defining the Cloud Maturity Model (CMM) for as-is and to-be
In the first step, we perform an end-to-end cloud assessment. A detailed Application Portfolio Rationalization (APR) was done for the current applications which were to be integrated/migrated. Further, a Cloud Maturity Model (CMM) for the current (as-is) and the desired (to-be) state was also prepared.
 Figure 1: Mapping the current landscape
Figure 1: Mapping the current landscape
In this process applications/workloads which required migration and re-designing/modernizing were identified.
A transformation and modernization roadmap was created with the help of a cloud solution architect, to phase the migration from CMM1 (as-is) to CMM4 (to-be).
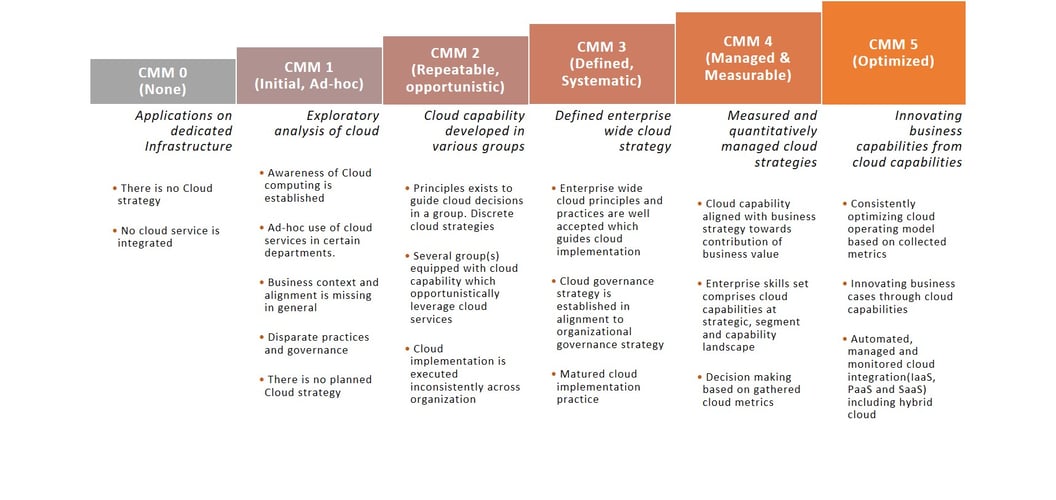 Figure 2: Cloud Maturity Model (CMM)
Figure 2: Cloud Maturity Model (CMM)
Once the journey and bottlenecks were identified, we created a proper cloud strategy, without compromising on the end goals. We also defined a tech stack, including the selected cloud. The selection of cloud can vary according to the end objectives and requirements. For example, Google Cloud Platform (GCP) may be preferred by an organization whose primary objectives are around AI/Data Science.
Similarly, Amazon EMR offers distinct advantages in specific scenarios over HDInsight of Azure. Based on the assessment, decisions like PaaS vs. IaaS, public vs. private clouds, choosing clouds like GCP or Azure or AWS, etc., were made. The next steps in our journey can begin only after this actual integration/migration/pipelining.
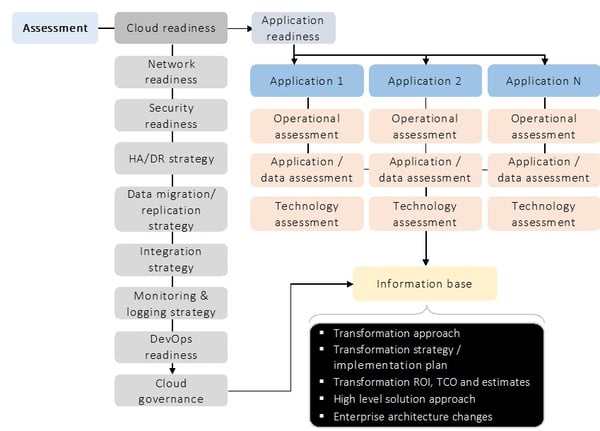 Figure 3: Cloud readiness assessment
Figure 3: Cloud readiness assessment
Step 2: Ensuring that privacy, security, and compliance requirements are met
Being sensitive to data privacy and security, the client had very specific requirements on PCI-DSS, GDPR, and HIPAA. Data on the cloud is a sensitive topic and should be addressed with all its completeness. Network security is equally important. Applications should use SSL/TSL level encryption. Standard secure encapsulation protocols such as IPSEC, SSH, SSL should be used when deploying a virtual private cloud. During the cloud assessment phase, we identified all such requirements.
To check the completeness of the assessment, a doneness document was required to call out all the checkpoints identified in the cloud assessment phase.
Before publishing the data to different teams and vendors, the identifiers had to be removed.
We solved some complex requirements like:
- Data scientists needed de-identified and de-sensitized data, so that Personally Identifiable Information (PII) remains completely anonymous.
- CRM folks needed masked data due to security concerns. The requirement had static & dynamic data masking. The main objective was to limit the exposure of confidential information to users not having the necessary privileges to access it.
- Different teams needed different levels of encryption and masking
a) Development and testing
b) Analytics and business reporting
c) Troubleshooting - Sharing the database with a third-party consultant/developer
Public cloud does not mean zero or less security, but it is a concept of shared security. Leading providers, such as GCP, AWS, and Azure, provide cloud-native security solutions. We met the compliance and security requirements, with tools and processes to achieve the desired results.Step 3: Choosing the right big data pipelines on cloud for SaaS
This step entailed selecting the right toolchain available on the cloud as a part of the strategy. As the requirement was cloud-agnostic, we chose a toolchain where the client can choose similar big data toolchains at almost the same cost of PaaS.
Once the toolchains were identified, clusters were sized according to the storage and computing requirements.
Big data is like a tree and Machine Learning/Analytics/AI are outcomes of the big data exercise. The big data toolchain should be extended to support Machine Learning, Analytics & AI by integrating SparkML, R-Studio, PySpark, TensorFlow, etc. The last step is to re-engineer data lineage, management, admin, and IT processes so that they can support big data with cloud initiatives.
All components were designed to be multi-tenant, configurable, scalable (including database), encrypted, licensed, and compatible with independent DevOps pipeline.
Step 4: Optimizing the cost of big data on the cloud
The costs of cloud with respect to big data technologies can be huge. However, it is essential to calibrate with multiple components of storage, network, memory, and computing. We advised the client to make a holistic assessment of the components and the duration of their requirements. Cost calculation should be TCO (Total Cost of Ownership) based and not just some on-demand, pay-as-you-go model.
Choosing the right architecture is imperative for success. We chose a mix of containers and serverless architectures along with Kinesis, Spark, and Hadoop distributions. We also separated the distributions into individual requirements which can be met with the best tools instead of being stuck with the vanilla offerings on the cloud. The net result was the best of Kafka, Spark, and Hadoop distributions as service options with support along with native cloud PaaS like ACS, Kinesis/EventHub, Lambda, RedShift/BigQuery, ELK, etc. The right balance between technology, requirements, and costs helped achieve the desired results.
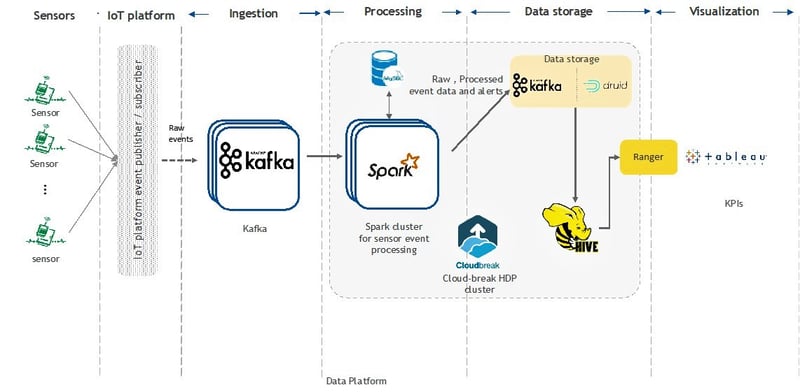
Figure 4: Sample data platform
We went for a 3-year commitment, which gave up to 70% discount in the long run, resulting in huge cost reductions. Being data-driven is a journey and not a project. Hence planning is required for the optimum utilization of computing, network, and memory.
On-demand total cost (3 year)
131235.12
On-demand total cost (1-year)
48969.14
Per month (on-demand)
3645.42
3-year reserved instances total cost
66032.78
3-year upfront cost
45627.62
Per month (calculated)
1834.24
Per month (storage cost)
566.81
Figure 5: Sample data calculations for on-demand and reserved instances (costs are in $)
We also kept an optimization of the costs to be around 5% for every quarter as the target. This can be achieved by noting the actual usage and patterns, and by choosing the right services on any cloud without compromising on the SLAs. It is equally important to keep the optimization as a Key Responsibility Area (KRA).
Step 5: MVP (Minimum Viable Product) and journey onwards
Once the roadmap was drawn and sizing was done, MVP was the first target. Developing MVP is like the validation of all the steps taken till date and giving the client confidence of immediate “win” in the next few weeks. We made a hybrid model (using cloud and on-premise data centers) and containerization as a part of the core solution. The lessons learned from the MVP were applied to the other deliverables.
On-boarding of multiple use cases was done only when the MVP stabilized, and after we were sure that this architecture would be stable for the next few years. However, we had kept things component-wise, which could be replaced if newer services/modules were found to be better in performance and costs. We integrated one-click install into the CI/CD pipelines so that different dev/prod/test stages could work according to their specific and secure data sets managed as per the security rules. A successful MVP was followed by a complete development lifecycle. Currently, it is in production with multiple happy clients.
Conclusion
Implementing big data technology can be a costly affair. Nagarro helps its clients solve the data chaos by employing a clear roadmap for adopting cloud strategy and following it to completion, making a substantial commitment of resources. Nagarro has developed several accelerators like Data Lake as a Service to help its clients onboard this journey faster. Nagarro’s cloud assessment tools are proprietary, allowing faster assessment of the client environment. We help clients improve their cloud maturity while making security and cost optimizations a part of the journey.

