

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


If you can’t place an order through an eCommerce store, you will switch to its competitor offering the same product. If it’s taking longer than usual to book flights via an online travel site, you will move to another platform. If you are unable to order groceries through a store’s mobile application, it will not take much time to install another app and place the order again.
This is what we do if our favorite sites fail, don’t we?
Sudden outages, interrupted services, and downtime substantially impacts a company's reputation and finances and its customers, who, today, have little patience to deal with slow service, let alone system failure.
So, how can companies avoid failures when downtime means disconnect? Enter, Resilience Testing!
Let's begin by understanding that irrespective of how good a software application is, eventually, something will go wrong. Failure is inevitable, but what's important is to be prepared for it and recalibrate. How is that possible?
By adopting an approach of resilience testing, we can be better equipped to deal with failure. The practice aims to ensure the system's ability to withstand stress, continue to perform in chaotic conditions, prevent loss of core functions or data, and ensure quick recovery in the wake of unforeseen, uncontrollable events.
Notably, resilience is not something that is achieved and then never considered again. It must be continuously tested—not only when systems start to break. Chaos engineering is a systematic approach to testing the resilience of a system and different types of failures. The development team can identify vulnerabilities well before an outage by persistently inducing failures in the system. There are several chaos engineering tools available that can help test and determine the resiliency of your software.
Importance of resilience testing
Instead of spending time running thoroughly orchestrated tests where the infrastructure is expected to be flawless, development teams must try and break the system in a way that doesn't make noise.
They can simulate failure scenarios and determine:
- how soon the system can recover
- what automation is required to make it recover faster
- what thresholds are required to help trigger early warnings to detect the outage before it happens
- what is the error budget or the time during which the customer's experience will be degraded, and,
- which indicators can be built to measure the system's health
One of our client's businesses depended on its channel partners. They developed commerce systems that enabled the channel partners to self-serve needs like generating quotations, placing orders, etc. Any inability to use these critical systems would mean losing business for the channel partners. To ensure the resilience of the essential operations, we set a service level indicator for response times on the login service. If the response time dipped by an unacceptable margin, it would imply that a failure is brewing. We built redundancy in the system to direct users through a backup login path that allowed them to continue business as usual with an acceptable slowness in the processing.
Tested observability and resilience practices are critical to giving your customers a better experience. Less downtime and improved application performance mean happy customers. An enterprise providing customs declarations service for cross-border trading realized that downtime on the application (that facilitates seamless movements of trucks by quick validation of declarations) would mean hours of traffic jams on the border. So, they decided to set up a dedicated practice focusing on proactive measures and managing incidents, helping them prevent outages.
By understanding how your system works and proactively testing it against any possible failures, you gain confidence in your teams, technology, and your ability to keep end-users happy, even when things go wrong.
Challenges faced
Many organizations still think that resilience built into the design is sufficient. For example, if there are two suitably sized load balancers, why should you still test? They don't consider the implications of network bandwidth or other downstream components.
Even in organizations where the need to undertake resilience is fully understood, there can be challenges. Testing is unlikely to be wholly undertaken by the test team. Resilience testing is a significant undertaking. It requires a representative environment and a skilled, knowledgeable team to design thoughtful experiments that test hypothetical scenarios.
Ways to overcome challenges
| Failure Type | Description | Resilience Strategy |
| Hardware failure | Failure of any hardware component like the computer, storage, or network. | Build redundancy into the applications by deploying high availability infrastructure and a secondary data center, active and active mode. |
| Heavy load/High volume | A sudden spike in incoming requests prevents the application from servicing requests. | Load balance across instances to handle spikes in usage. Monitor load balancer performance/load factor to finetune or add more capacity. |
| Transient failure | Requests between various components fail intermittently. End user requests will fail when this isn't handled properly. |
Retry transient failures. The client software development kit (SDK) implements automatic retries in a way that's transparent to the caller. Example: Network connectivity or database connection drop/timeout |
| Dependency service failure | This occurs when any service on which the application is dependent is not functioning correctly. |
Degrade gracefully if a service fails without a failover path, providing an acceptable user experience and avoiding cascading failures. Example: Display error message/queue the requests. Other functions of the application should continue to operate. |
| Accidental data deletion or corruption | Customers mistakenly delete critical data or data that has been corrupted due to unforeseen reasons. | Back up data so it can be restored if there's any deletion or corruption. Know how much time it would take to restore a backup. |
| Application deployment failure | A failure that takes place when updating production application deployments. | Automate deployments with a rollback plan. |
| Datacenter Failure | DC failure due to power grid outage. | Build redundancy into the applications with a secondary data center. |
System resilience testing: The ideal approach
Resiliency testing of a system helps absorb an issue's impact, so it recovers quickly while providing an acceptable level of service to the users.
To kick-start, teams must understand the architecture, design, and infrastructure of systems and build test strategies by:
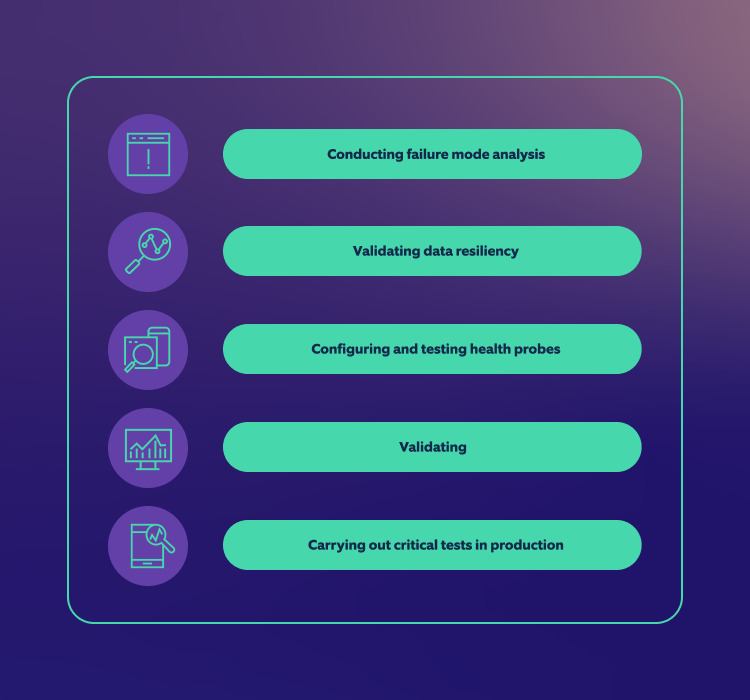
- Conducting failure mode analysis: Identify all the components and interfaces (internal and external) along with the potential failures/timeouts at every point. Once they are identified, validate that there are alternatives to failure.
- Validating data resiliency: Ensure that a standard operating procedure (SOP) is in place to validate application and data availability in case the system that originally hosted the data breaks down.
- Configuring and testing health probes: From an infrastructure point of view, design and test health probes for load balancing and traffic management.
- Conducting fault injection tests: Carry out fault injection tests for every application in your system. These may include deleting data sources, shutting down interfacing systems, consuming system resources, deleting certificates, etc.
- Validating network availability: Validate that all networks are available and there is no data loss due to latency.
- Carrying out critical tests in production: Ensure that the tests are well-planned and there is an automated roll-forward and rollback mechanism for code in production in case of failure.
You may refer to our article on the 4-step approach to resiliency testing and orchestrating chaos engineering smoothly.
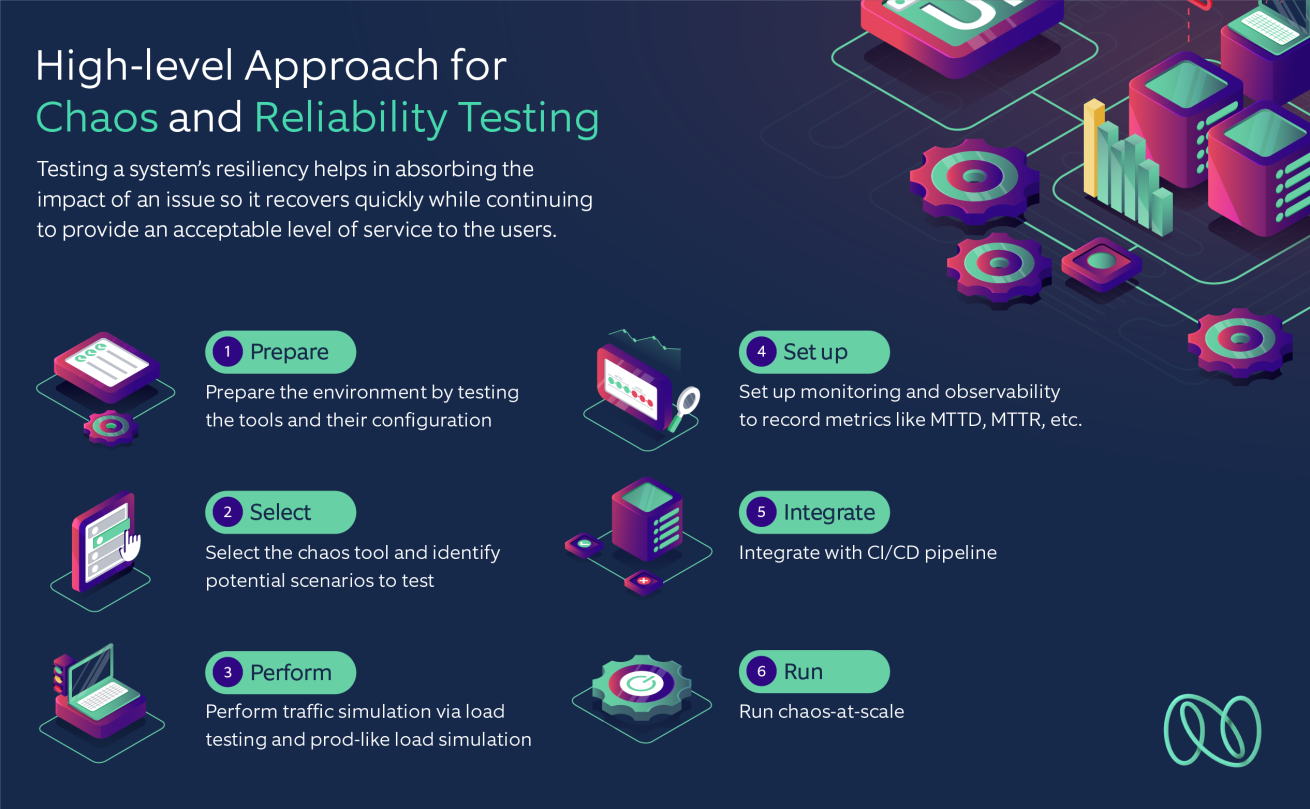
Here's a high-level approach we recommend you follow for chaos and reliability testing:
- Prepare the environment by testing the tools and their configuration.
- Select the Chaos tool and identify potential scenarios to test.
- Perform traffic simulation via load testing and prod-like load simulation by changing certain metrics. Attack types and targets include redundancy tests, network latency, packet loss, etc.
- Set up monitoring and observability to record critical metrics such as MTTD, MTTR, SLI/SLO observability-based scorecards, etc.
- Integrate with CI/CD pipeline.
- Run chaos-at-scale.
Next step? Start with GameDays to test the resilience of systems by putting them under stress through regular simulations.
It's here—the day you get to prove that your system is resilient against an outage in production.
GameDay is an interactive team-based learning exercise designed to give players a chance to put their skills to the test in a real-world, gamified, and risk-free environment. It is a dedicated day for running chaos engineering experiments on the systems to practice how you, your team, and your supporting systems deal with real-world turbulent conditions.
The main purpose of GameDays is to prepare the systems for any failure. You can plan a GameDay to test hypotheses and evaluate if the systems are resilient to various failures. In case they are not resilient, you can fix these failures before they impact the user experience.
How to Plan a GameDay
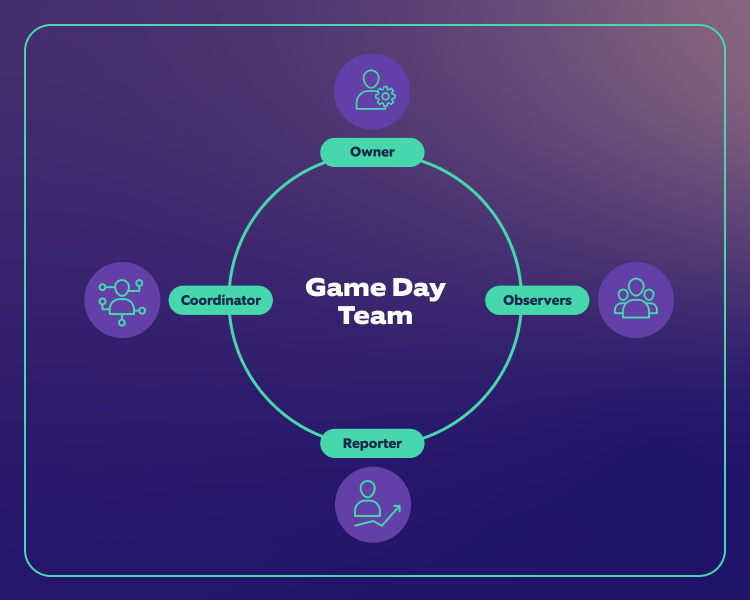
To get started, you need a team of engineers who developed and/or support the application, a team lead, and a product manager(s). Each member will be assigned these roles:
- Owner: Owns the GameDay, prepares the plan, schedules, and decides if and when to stop the experiment.
- Coordinator: Prepares the GameDay, coordinates other team members, and starts the attack.
- Reporter: Collects all the information, draws inferences, and reports the result of game day.
- Observers: Gather data from the monitoring tools.
Once you have prepared the team, here is the framework we recommend you follow to run a GameDay:
| Before the GameDay | During the GameDay | After the GameDay |
|
|
|
Nagarro's capabilities
At Nagarro, we can help you begin your resilience journey to ensure minimal disruptions to your service or software.
Failures will happen, but you can choose to identify them easily with a clear head at 2 p.m. instead of being confused, half awake, and stressed out at 2 a.m. Connect with us today!


