

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)

EuroSTAR 2026 in Oslo caught the software testing and quality engineering community at a turning point in its relationship with AI.
The enthusiasm around AI-assisted testing hasn't faded; it’s far from it. But the conversations at this year's conference carried a different weight. The big, sweeping promises have given way to sharper, more practical questions: Where does AI genuinely help? What needs careful governance? How do you evaluate a GenAI system when its output isn't always deterministic? And how do quality teams translate confidence, risk, and readiness into language that business leaders can act on?
These questions ran through Nagarro's presence at EuroSTAR this year. Nagarro’s presence at EuroSTAR this year. Across our sessions, we explored three connected themes: orchestrating AI across the testing lifecycle, evaluating GenAI quality in meaningful ways, and helping QA teams turn technical insight into leadership confidence.
From automation to orchestration
Test automation has long been synonymous with speed, faster execution, broader regression coverage, and fewer repetitive manual tasks. Those goals haven't gone anywhere, but AI is reshaping how teams think about automation itself.
In "Multi-Agent Cooperative Testing: Automation to Orchestration," Nagarro's Manisha Mittal and Apurva Singh laid out a vision for moving beyond isolated AI-assisted testing activities toward coordinated, role-based agent systems. Picture specialized agents each handling a different piece of the testing lifecycle: API validation, regression execution, risk analysis, security scanning, flaky-test detection, and self-healing automation, working together rather than in silos.
What gave the session its energy, though, was what happened after the presentation. Attendees pressed on the practical details: How does this integrate with existing QA and DevOps toolchains? What about cost and token usage? Which models work best for which tasks? Where are the security guardrails? And what are the real limits of self, healing? These are precisely the questions any team should be asking before introducing AI-enabled, enabled testing into a live delivery environment.
The takeaway was straightforward: orchestration isn't just about connecting agents. It's about putting the right controls, context, and human oversight around them.
For those who missed the session in Oslo, "Multi-Agent Cooperative Testing: Automation to Orchestration" will also be available as part of the EuroSTAR Global Series.

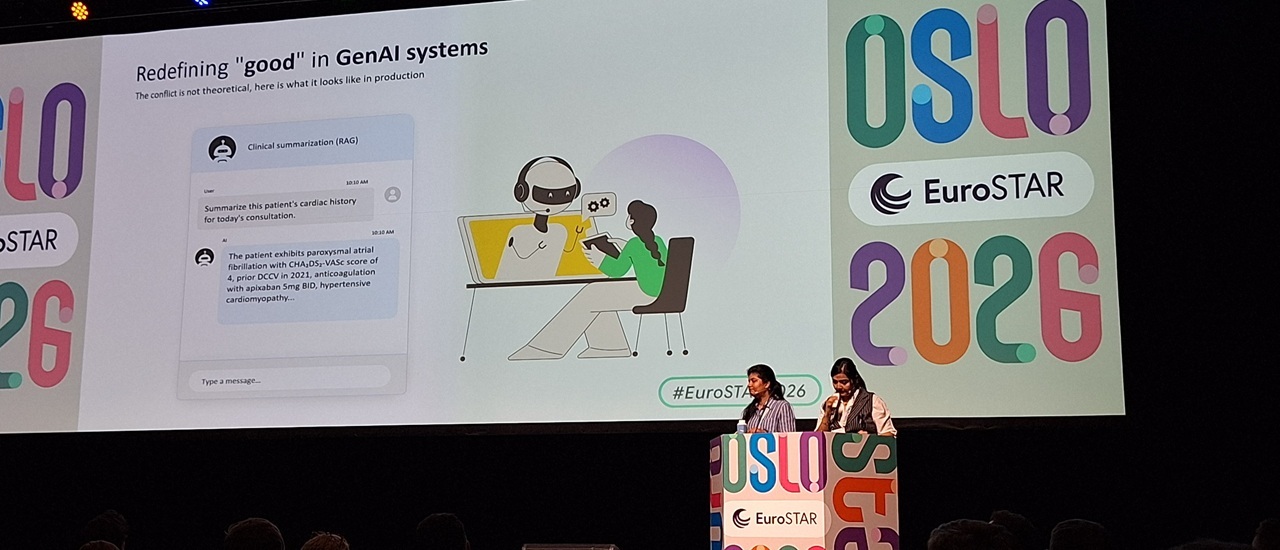
Evaluating GenAI beyond generic scores
If orchestration was one pillar of the AI conversation at EuroSTAR, evaluation was the other.
Traditional software testing rests on a familiar assumption: a given input should produce a predictable output. GenAI breaks that model. There may be several perfectly acceptable responses to the same prompt, and what counts as "quality" shifts depending on the context in which the system is used.
This was the territory covered in "Metrics That Matter for GenAI Evaluation," presented by Nagarro's Anamika Mukhopadhyay and Deepshikha. Their session challenged teams to move past generic model, level scores and instead define evaluation criteria anchored to real requirements for the system as a whole.
Consider the range of dimensions that quality can span for a GenAI application: factual consistency, relevance, safety, robustness, tone, reasoning quality, and business usefulness. A customer-facing assistant, an internal knowledge tool, a summarization feature, and an autonomous agent will each demand a different evaluation lens. One-size-fits-all benchmarks simply won't cut it.
That reframes evaluation as a quality engineering challenge, not just a model benchmarking exercise. Teams need to define what "good" looks like for their specific use case, measure it consistently, and feed the results back to improve the system over time.
For many organizations, this is where quality engineering has the opportunity to play a much broader role. As AI becomes embedded in business workflows, quality teams are well positioned to create the confidence needed to move from experimentation to reliable adoption.

Making management listen
A third thread at EuroSTAR kept surfacing in sessions and hallway conversations alike: quality teams often sit on valuable insight, but it doesn't always reach leadership in a form that drives decisions.
Dashboards, test counts, defect lists, automation coverage , all useful artifacts. But on their own, they rarely answer the questions that leaders care about most: Are we ready to release? What risks remain? What could affect customers? Where do we still have uncertainty? How confident should we be?
In his tutorial "Make Management Listen: QA Stories That Build Confidence," Nagarro's Chris Mastnak explored how QA teams can reframe quality communication to connect more directly with business decisions. The focus: moving from activity, based reporting, "here's what we did”, to narratives built around coverage, risk, and confidence, "here's what it means."
The shift matters more than it might sound. When quality teams explain not only what they tested but what that testing means for a release decision, they step into a more active role in business planning. Quality engineering becomes less of a final gate and more of an ongoing source of decision support.

What we took away from Oslo
EuroSTAR 2026 revealed a quality engineering community that is growing more deliberate and nuanced in its approach to AI.
The talks and presentations offered real substance, but some of the richest moments came afterward , during attendee Q&A sessions, roundtable discussions, and informal conversations over coffee and drinks. Those exchanges provided a more candid picture of where organizations and practitioners actually stand in their AI adoption journeys.
We met teams already running sophisticated GenAI evaluation programs with mature processes and clear measurement frameworks. We also spoke with practitioners still working through more foundational questions: what to test, how to evaluate AI systems, and which metrics genuinely matter. That range of perspectives underscored both how far the industry has come and how much ground remains.
For many attendees, the conference seemed to serve as a catalyst, helping teams shape their approach to AI adoption, identify meaningful use cases, and gain clarity on where to start. It was a good reminder that while formal presentations can spark ideas, open and honest peer-to-peer conversations often yield the deepest insights.
The conversation isn't simply about adopting new tools faster. It's about understanding where AI creates value, where it introduces risk, and what teams need in place to use it responsibly. It's also about communication, helping stakeholders understand what quality signals mean and how much confidence they can place in them.
For us at Nagarro, the conference was a valuable opportunity to share perspectives from the stage, exchange ideas with the testing community, and, just as importantly, listen to the questions practitioners are asking as they bring AI into real, world quality engineering.
The strongest message we took from Oslo: AI will continue to shape how testing and quality engineering evolve, but its value will depend on how deliberately teams apply it. Purpose, evaluation, governance, and clear communication will matter just as much as the technology itself.
Want to know more about amplifying human potential with AI in Testing? Explore our AI in Testing appraoch.

