

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)

.jpg)
The concept of a feature store was first launched by Uber in 2017 when it launched the Michelangelo Machine Learning platform. This Feature Store played an essential part in operationalizing Uber's machine learning projects. The aggregator used the ML platform to predict the estimated food delivery times for UberEATs. Eventually, multiple other tech organizations like Google and Amazon followed suit, and soon feature stores became an important component of an organization's ML stack.
What is a feature?
To understand a feature store, it is essential first to define a feature. Features are core inputs for an ML model. We can define features as descriptive attributes or variables. If features are selected appropriately, engineers can build impactful ML models.
Features are a result of feature engineering -a process that extracts information from a raw dataset to solve a problem. It ranges from basic transformations like aggregations to advanced feature transformations like word embeddings. The goal behind creating features is to engineer the dataset to allow the ML model to produce better results. The Quality of ML models significantly depends on the features fed into them.
What is a feature store?
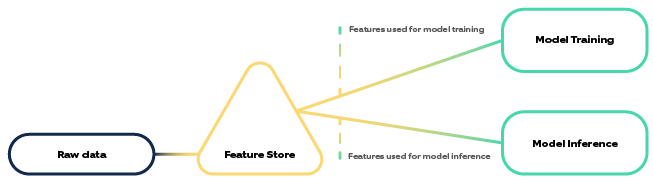
"A Feature Store is a centralized repository that stores curated features."
It is a data layer that helps data scientists, machine learning engineers, and data engineers to work in collaboration and share and discover new features for ML models. A feature store works as an interface between raw data dumps, ML models, and their inferencing. This provides consistency in data during model training and model inferencing.
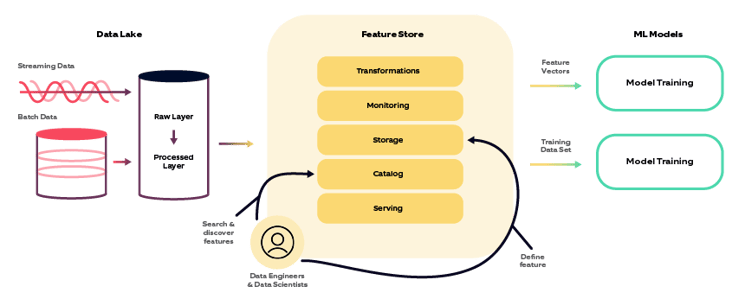
Why do you need a feature store?
ML engineers will have to duplicate and repeat all feature engineering steps used in ML model training in the absence of a feature store. Existing features undergo multiple changes during the engineering phase. The transformed features are then used by different ML models for training purposes. Finally, the best model is selected and deployed in the production environment for further inferencing.
Software engineers/data scientists create codes and computing features during model training and then repeat the process during production, leading to duplication. And duplicate codes can significantly increase the error rate. This also leads to troubleshooting errors which is a cumbersome process.
In the absence of a features store, production teams may also face challenges in:
- Accessing the right raw data
- Building features from raw data
- Combining features into training data
- Calculating and serving features in production
- Monitoring features in production etc
Feature Store helps:
- Maintain consistency between ML Model training and inference and leads to better model accuracy
- Eliminate online/offline skew
- Collaborate, share, and reuse features
- reduce duplication across ML models and teams, enabling faster model development
- Provide features that verify data validity and check data quality, versioning, lineage, and regulatory compliances
Key functions of a feature store :
- Multi-source data consumption: the Feature Store can read data from multiple sources and load data through:
− Various streams
− Warehouses
− Data files - Data transformation: One of the key benefits of the Feature Store is that it makes it easy to use different types of features together in the same models. Data scientists can extract data from different sources. The feature store helps the model process, join or transform data reliably and consistently, and monitors the action's completion.
A Feature stores transformations like one-hot encoding or labeling data or encoding text data that a model can further process. Feature Store will ensure consistency between these transformations with proper analytics and monitoring that ensures the data has been completed before it is served to the model. - Search & discovery: One of the major objectives behind the feature store is to increase collaboration among teams by sharing searchable features created by different teams and models in an organization.
- Feature serving: A good feature Store enables sharing features with registry information to ensure the features are standardized and consistent across all teams' models.
- Data storage
− Offline Feature Store: Offline storage layers store feature data for months or years for training purposes. It is often stored in data warehouses or data lakes like S3, BigQuery, Snowflake, Redshift etc.
− Online Feature Store: Online storage layers persist feature values for low-latency lookup during ML model inferencing. They only have the latest feature values for each entity, for modelling the current state of the world. They are usually implemented with key-value stores like DynamoDB, Redis, Cassandra, etc. - Monitoring: It is one of the very important aspects of a feature store. It helps in identifying completeness, correctness, and the quality of data. Monitoring further helps the system stay updated and free from bugs in the event of any error and complexity.
When do you need a feature store?
It depends! One must-have Feature Store while working on a project where the requirement is to deploy models at scale. You can avoid the usage of feature Store when working within a small team or on a small project.
How can Nagarro help?
Nagarro can build and implement a feature store based on the requirements across various domain-based business use cases.
In one of our large engagements, focused on reducing fruit loss in the supply chain, we are leveraging the power of a feature Store. Our client's system reads data from various heterogeneous systems like SAP, inventory systems, etc., and maintains their data lake.
Our feature store reads the variety of candidate feature data from these data lakes, fed to our ML model training, model inferencing, and model retraining pipelines. This architecture helps us share features across the ML models and save a lot of time for productionizing these models. It also helps data scientists and ML engineering teams to work in synch with negligible complexity.
-2.png)
