

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


Supermarkets, shopping malls, and retailers once defined the shopping experience for most of us. Fast forward to today, online shopping has become the norm. Witnessing a huge growth of 14.2% in 2020 and 50.5% in 2019 in the US, e-commerce has become an integrated part of people’s lives. Now, as an online retailer, you cannot afford your website to go down. Even the slightest of delays or outages can lead to losing out on customers, a tarnished brand, and lost revenue. Meanwhile, constant pressure exists to innovate and keep up in the ultra-competitive world.
What do today’s shoppers expect? According to a report by Salesforce, State of the Connected Customer, 88% of customers say the company’s experience is as important as its products or services. So, what can you do to improve user experience and stay resilient? Adopt resilience engineering! When you build e-commerce stores that are resilient to outages, you can ensure that you do not lose business even on some of the biggest sale days and that customers can purchase products seamlessly.
Let’s explore this in more detail.
Be proactive rather than reactive
"Chaos Engineering is a choice between a ten-second controlled failure and a multi-hour uncontrolled failure."
– Bruce Wong, Head of Data Platform at DataBricks
In a competitive industry like e-commerce, it is important to keep your services up and running round-the-clock to serve customers without any interruption – from product search to completing the purchase. Your store must be digitally resilient to unforeseen, disruptive incidents to keep customers satisfied with the purchase experience and ensure their loyalty to your brand. After all, the cost of downtime can be high, both in terms of finance and reputation, as even a small delay in accessing features in your website can lead to your customer jumping to your competitor’s site in one click.
Resilience doesn’t only mean that your systems don’t fail but more importantly, it means you do not fail your customers and that they can trust you for the products/services you offer.
Chaos engineering can prepare for any unforeseen failure of a process or service by manually injecting a failure into the system to make it resilient with each iteration eventually. The aim is for you to proactively identify any system error(s) well before any of your customers experience it.
If you are wondering why chaos engineering, let’s start by looking at an example where your applications are terminated one after another, significantly impacting user experience. However, you do not see a memory or CPU spike. After testing, you identified that writing logs in a file within the container led to running out of disk space.
Some of the common issues that organizations experience at the application level include CPU/Memory spikes, network latency, application crashes, and disk space. It is pivotal to have newer testing methods to make the infrastructure resilient against such disasters. As we leverage microservices architecture, we often observe that one slow service drags the latency up for the whole chain of systems. In fact, with microservices, we are now experiencing multi-point failures in distributed systems.
You can read more about the importance of chaos engineering in our blog here.
Case in point: Testing the resilience of an e-commerce store
Let’s take an example of SAP Commerce Cloud (formerly Hybris), an industry-proven e-commerce and digital marketing platform solution for B2B and B2C enterprises that have experience in delivering scalable and extensible multi-brand, multi-region, and multi-currency implementations. When an e-commerce store is built on such a platform, many considerations should be accounted for to test resiliency. Below is a high-level view of on-premise deployment and targets identified for building reliability:
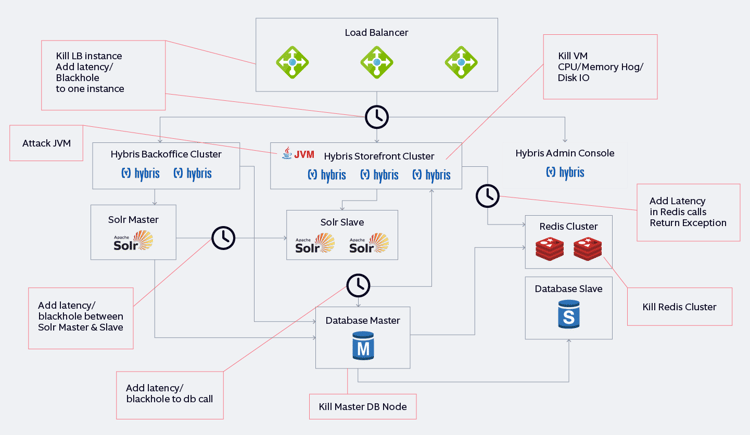
On-prem reference deployment architecture for building reliability in e-commerce stores
Now, let us look at a few scenarios where chaos engineering can be implemented to test the resiliency and reliability of the above architecture:
| Serial No. | Component | Indicative Technology | Test Scenario | Chaos Experiment | Expected Result |
| 1 | Application load balancer | NGINX running on VMWare |
Fault tolerance and high availability |
Use a VM-PowerOff to shut down one load balancer. | Other surviving load balancer instances should continue to serve new incoming requests. In-flight transactions that fail should be re-processed with retry logic, wherever feasible. |
| 2 | Storefront interface | Hybris Storefront instance running in JVM | Validating load balancing and automatic failover of backend services through health checks | Use a blackhole attack to drop all network traffic between the Load Balancer and one of the backend worker instances. | There should be no failed requests. All requests should be forwarded to the healthy instance. If any requests fail because the Load Balancer can’t contact the backend, then we know we need to reconfigure our health checks. |
| 3 | Storefront interface | Hybris storefront instance running in JVM |
Application performance and impact on high resource utilization |
Inject CPU/Memory Hog in one or more backend services. |
Response times for transactions may increase during stress duration, but there should not be any failed transactions. Gain insights on application performance thresholds and behavior under high resource utilization |
| 4 | In-memory data store | Redis Sentinel |
Automatic failover and high availability |
Shut down the Redis master instance. |
A Redis replica instance is promoted to the master, and there are no transaction failures. |
| 5 | In-memory data store | Redis | Measure latency | Inject latency to the data grid host. | There should be no impact on caching performance. |
| 6 | Product search | Apache SOLR | Replication and consistency | Use a blackhole attack to drop all network traffic between the Solr master and the slave server for a stipulated amount of time. | Indexes should be synced up between master and slave eventually without any corruption or issues. |
*The scenarios and experiments listed above are not exhaustive and indicative in nature. They depend on varying factors such as technology components, deployment architecture, infrastructure components, etc.
Choose a chaos engineering tool
Several tools in the market offer various features, attacks, automation support, environment support, usability, enterprise support, etc. You can select/choose a chaos engineering tool that aligns with your requirements and aims to test resiliency at each environment level. Some of these tools are:
-
Gremlin
Gremlin is a SaaS (Software-as-a-Service) based chaos engineering tool, sometimes referred to as CaaS (Chaos-as-a-Service), which provides a set of attacks related to system resources, states, and networks to test the resiliency of the systems. It offers three sets of attacks, but it is the user’s responsibility to determine which attack best suits the environment and how multiple tests can be clubbed together to test the resiliency of the complete e-commerce environment. -
LitmusChaos
LitmusChaos is an open-source chaos engineering platform. It is a Kubernetes native designed for K8s-based applications. It provides several experiments for testing containers, pods, and nodes. It also provides a centralized public repository of experiments called ChaosHub so anyone can contribute experiments. -
Chaos Monkey
Chaos Monkey was the first chaos engineering tool developed by Netflix when they moved from on-Prem servers to AWS cloud. It is an open-source tool with no licensing cost. It supports attacks to terminate the instances randomly to test how resilient the system is at the infra level (with support for multiple public clouds like AWS, Azure, and GCP).
Observability: How well do you understand your system?
In case of an unexpected outage, you need to see where your system failed. However, more than that, you need to build systems that can give you insights into when things are more likely to fail. Observability helps in measuring the service level quality of your application performance. With operational dashboards at your fingertips, you can get visibility into your eCommerce site’s entire technology stack and system health to be able to troubleshoot any potential issues that may be affecting your customers’ shopping experience.
The three dimensions across which you can measure the performance of your web or mobile application are:
- Availability: The first step is to verify and ensure that the eCommerce site is up and running. You can check this by monitoring the site’s performance, setting up availability alerts, and tracking uptime Service Level Agreements (SLAs).
- Functionality: After you establish that the site is up and running, the next step is to ensure that it functions seamlessly.
- Speed: Alongside maintaining availability and functionality, you must also ensure that the site is working fast enough for customers to be able to complete their transactions smoothly.
While there are hundreds of metrics that you can monitor, ‘Site Reliability Engineering’ by Google mentions four golden signals to monitor tracking latency, traffic, errors, and saturation.
- Latency: How long do requests and actions take to complete
- Traffic: Network usage, number of connections, IOPS, etc., that indicate the volume that is being processed by the system
- Errors: Number of HTTP 500s, non-zero return code, etc.
- Saturation: 100% CPU, disk, or network utilization that indicates an overload
Tools like Grafana, Dynatarace, etc., provide a real-time view of the system’s operational data and enable you to optimize its performance & deliver an enhanced digital customer experience.
How does digital resilience benefit e-commerce?
Some of the most common benefits that businesses can achieve by implementing chaos engineering and ensuring that their systems are digitally resilient are increased availability and decreased mean time to resolution (MTTR). Let’s discuss more advantages in detail below:
-
Improve customer experience
By building digital resilience, you develop a resilient customer buying journey from adding to the car to checkout and payment processing. This, in turn, helps deliver a seamless customer experience. -
Prepare for unexpected outages and incidents
With resilience engineering, you can proactively identify any failures and reduce the chances of service disruptions that cause downtime. It also helps prepare for traffic spikes and prevents revenue loss. -
Protect your brand reputation
When you are able to identify system failures proactively and reduce outages, you can prove more reliable than your competitors and, in turn, keep your brand reputation intact.
Implementing chaos engineering the right way is key to realize these benefits and more. Check out the chaos engineering best practices and steps to get started.
Conclusion
As an online retailer, don’t you want to anticipate outages before they occur and ensure that failure in one area of the architecture will not cause the entire system to fail? Creating controlled chaos can help you enhance system resilience, deliver uninterrupted services against outages, predict unanticipated surges in traffic volumes as well as prevent cybersecurity attacks.
Partner with Nagarro so we can support you in just that. To learn more, check out our resilience engineering services.



