

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


To say that databases are an integral part of any enterprise would be a euphemism. While DevOps practices help enable their delivery, managing a database can be challenging.
The primary reason why managing database changes is a tedious process is that it requires a thorough and careful analysis of the schema change in the application. Since such a change is sometimes a manual and incomplete process, it can cause defects. And don't forget, while you are fixing it in the schema, competitors are innovating faster and moving ahead! A database change can even delay the deployment of an application.
According to a research report, database deployments have been a bottleneck for the second consecutive year. More than 90% of the respondents reported difficulties in accelerating database deployments.
Such a bleak situation makes it imperative to find efficient solutions to database deployment challenges. Want to know how DevOps can help overcome the database bottlenecks? Let's get started!
Making a case for databases in DevOps
Imagine you are in the following scenario:
- A team of developers is working on a new feature for an enterprise. One developer commits the code to the source code repository.
- A few tables are created in the database for the new feature. The developer commits the SQL file to the version control repository to suffice this need.
- The developer waits for the CI/CD pipeline that gets triggered automatically, builds the code, generates artifacts, and deploys them to a lower environment.
Here's the challenge: how can the SQL file automatically be deployed to the databases from the same pipeline to ensure backward compatibility?
Developers expect DevOps automation to handle this and automatically deploy the SQL file to the databases. Automated database deployments are tricky and not like application deployment. Managing their release and deployment cycles is even more complex. Databases have tables, views, procedures, functions, indexes, constraints, with more complex DDLs and DMLs.
An overlook change to a production database can be devastating to an organization's finances and reputation. The database is often a common access point for multiple applications or systems, impacting multiple processes. IDC reports that the average cost of a critical application failure per hour is $500,000 to $1 million. Besides, of course, the damage to the brand's reputation.
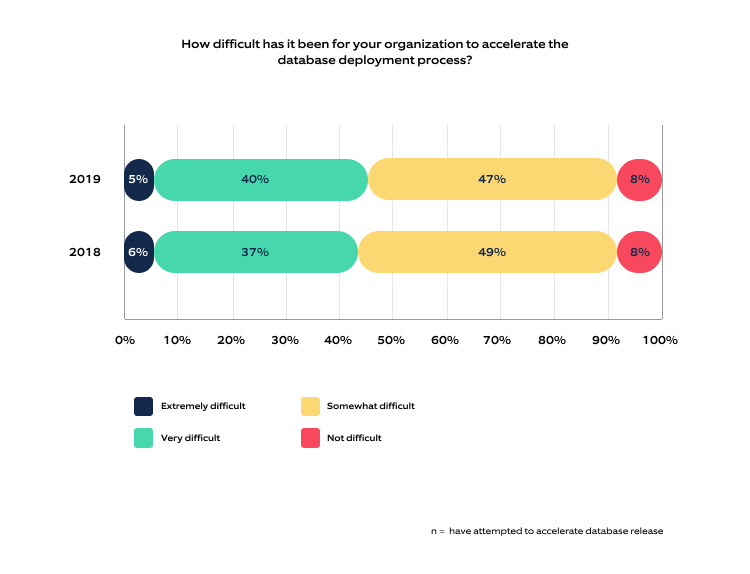 Source: 2019 State of Database Deployments in Application Delivery report
Source: 2019 State of Database Deployments in Application Delivery report
As per the above report, 40% of respondents faced difficulties automating the database deployment process.
Challenges in managing databases
Data management
Data in the production environment seamlessly ensures code and data work. But ideally, developers shouldn't use production data due to its criticality and the need for masking/encryption.
Provisioning data
A new feature is developed and is ready for production. The developer needs data to test the feature correctly, and it doesn't make much sense to use old data.
Data persistence
Continuous deployment for databases is way more complex. Data should be persistent in non-volatile storage. For instance, the new feature requires a schema change where the data must be migrated to the new structure. This is not a simple task without the right tools and processes in place.
Tracking of SQLs
If we have executed SQLs in the database, we cannot execute the same SQL again (as it will fail). How will the CI/CD pipeline keep track of SQL files to be executed and the new SQL files to be deployed to the database?
This is where tools like Flyway and Liquibase come in, as they implement CI/CD for databases. We integrate these tools into the CI/CD pipeline to keep track of the executable and new SQL files in the database.
DevOps for databases encourages developers to shift the process to the left, with the help of tools that enable it to run more smoothly within the CI/CD pipeline. DevOps for database ensures:
- All database artifacts/SQL files are version controlled
- Incremental SQL scripts are deployed
- Avoiding any situation where an already applied script was modified in version control (instead of adding it as an incremental SQL script)
Best practices to follow while implementing DevOps for databases
These best practices help in building a database with DevOps to improve software quality and expedite the release:
- Version control is the first step to incorporate DevOps when building the database. Leveraging database versioning as part of source control enhances productivity.
- Enable faster feedback: A critical aspect of any good software is the ability to leverage automatic feedback loops to validate the database changes. For example, if the code doesn't pass the validation rules, the developer should receive feedback for fixing it.
- Make small and incremental changes: A smaller change is always easy to manage, especially in databases. If a bad database change gets deployed, it can force the team to bring down everything and spend several days rectifying it. Using a tool for tracking the changes is the key.
- Backward compatibility: Enabling database version control helps maintain backward compatibility with previous versions. This makes the data columns nullable instead of null columns.
- Security: Security is always a much-neglected aspect while managing databases, particularly the access to tables, views, stored methods, and procedures. One way out is to set up permissions from the start. When a developer tests the application and fails, it states the incorrect permissions. This means that by the time the change is deployed to the staging environment, the permissions are fixed, and there is no risk of missing any permission.
Conclusion
With proper practices in place, the database is no longer a bottleneck. Database changes can sync with application changes through CI/CD pipelines. While considering a database change, the above-mentioned best practices will ensure the best return on investment.
Want to ensure your databases keep running smoothly? Nagarro's experts can help unscramble your databases with DevOps! Explore our offerings and get in touch with us.

