

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)

Buzzwords like ‘data is power’ or ‘data is the new oil’ have become clichéd today. Of course, we generate a deluge of data in this highly competitive user-centric business landscape, as organizations focus on emerging technologies such as embedded connectivity, IoT, blockchain, conversational AI, artificial intelligence, and machine learning. But what is the quality of data? Is it good enough to be collected, consumed, and interpreted for business usage? And how should we use this data?
|
According to a Gartner report, 75% of enterprises will switch from piloting to operationalizing AI, driving a 5X increase in streaming data and analytics infrastructures, by end of 2024. |
In this blog, we are addressing the two major ways in which data can be used:
- As an input to an application (which can be of any technology) - this data is important to get the response of the application right.
- For business intelligence and analytics.
Data and quality assurance
High quality data is necessary for accurate interpretation and application validation. Accurate data interpretation and forecast can turn out to be the game changers in business decisions. The correct set of data is indispensable not only for decision-making but for technical solutions using AI/ML, deep learning, etc.
In the absence of clean, correct, and high quality data, solution-oriented data analysis and modeling can get inhibited. This leads to inaccuracy in business forecasting, identifying new opportunities, technical models, and algorithms to implement in emerging technologies.
QA comes into the picture when data validation is critical to handle with the conventional testing approach. A QA needs to be aware of the expected outcome from the data, whether it is being used as input to the model or as an input to the business analytical decisions. With an expected output, they need to know the data journey too – such as about the data sources and rules, conditions, formatting, feature extraction – before adding their input to any model or analytical solution.
Challenges
We can face some challenges while data testing for an application (with big data, IoT, mesh of devices, artificial intelligent algorithms) and with data analytics, like:
- Lack of technical expertise and coordination
- Heterogeneous data format
- Inadequacy of data anomaly identification
- Huge data sets and real-time stream of data
- Understanding the data sentiment
- Continuous testing and monitoring
Approach
Leveraging data and analytics automation solutions is a data-driven approach that can help resolve continuous data quality from source to real-time stream. Data and analytics automation are an end-to-end, in-house solution. This automation framework also helps with huge datasets, as it works based on mapping data with the required use case queries for structured and non-structured datasets.
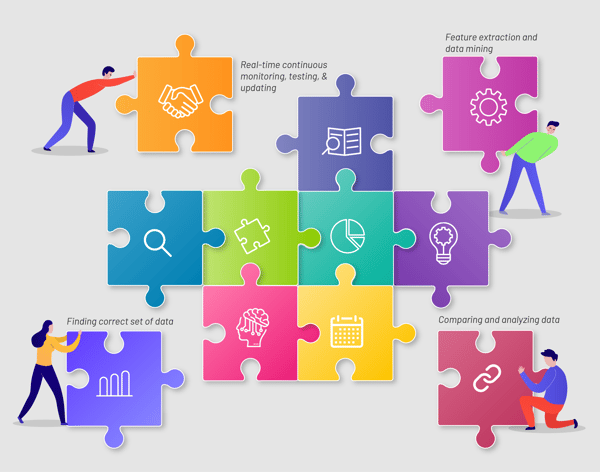 4 Steps in the data & analytics automation solution
4 Steps in the data & analytics automation solution
1. Finding the correct set of data
This step is crucial as it identifies the correct data set or at least the one with the correct data source. To achieve accuracy in the in-built model, various methods have been used to find the correct set of data. These methods include tokenization, NLTK, TextBlob Python library, normalization, stemming and lemmatization, and rule-based classification.
Here are the steps to find the correct set of data:
- Break the use case based on a smaller group, using the tokenization approach.
- Remove the unnecessary common words like ‘a’, ‘the’, ‘an’, ‘is’, etc. by using python existing library, NLTK, and TextBlob.
- Keep the same formatting and normalize if any data is manipulated by using the classification method.
- Identify and classify similar words like ‘enhancing’, ‘enhance’, and ‘enhanced’ to one ‘enhance’ by using stemming and lemmatization.
2. Feature extraction and data mining
Extracting data features helps in analyzing data as per its business usage. This includes checking for data corrections, identifying any missing data, understanding data biases and being fair with business usage. This can be done in the following way:
- Use a Python library for data binning and to classify it based on business requirement and implement it in the model.
- Perform Apriori testing, decision tree algorithm.
- Use machine-learning (ML) methods such as Naïve Bayes to check the accuracy of data, identify the outliers and classify them based on the use case. Also, for simpler cases, rule-based classification is done because it is more accurate to the use case.
3. Comparing and analyzing the data
Now, we validate collected and consumed data for a given use case with different automatic test data generation by using comparison methods. These validations are performed to estimate accuracy and interpret any systematic error. Based on the use case, an automated framework is developed, which uses the rules, conditions and queries to compare and analyze the data. It is more important to analyze the data based on business needs and the type of data we collected so that comparison with existing data is done.
4. Real-time continuous monitoring, testing, and update
A data model manager helps in identifying any outlier entrance to data input, thereby reducing the anomalies. How data is entered in the model and how a data model test can be enhanced by using continuous testing and monitoring, can be seen in the following image:
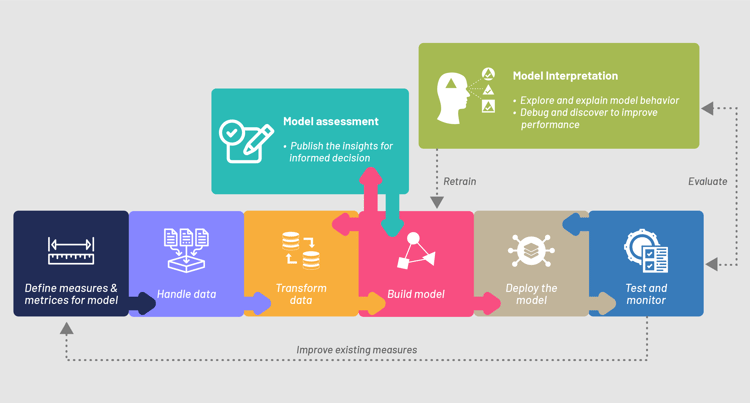
Flowchart depicting the implementation of data in a model
Benefits
Nowadays, we have a lot of structured and unstructured data that is created and stored. All this data is meaningless for business if it does not aim to process and generate useful information. As we have seen, data is used in two forms:
- To create a model to predict, prescribe or describe the business requirement – this is used in different aspects of AI.
- To add value to a business in the form of reporting based on data – known as business analytics.
For both forms, data is the dominant factor. By using an analytical automation framework to validate the quality of data, we can improve the productivity and efficiency of business decisions and requirements. Some of the benefits of this analytical automation framework are:
- Optimizes effort to process the data
- Agnostic to data platforms
- Reduces the data quality testing effort via various algorithms and methods
- Improves business decision-making based on the correct data analysis report
- Increases market target and strategy decisions, based on data
- Maximizes clarity and confidence for a model through feature extraction and data mining
- Ensures 100% test coverage of data and model with real-time monitoring and update
- Increases data accuracy and fairness and reduces biasness in a model
In a nutshell, application testing and business intelligence generation are based on data. The same framework is implemented for validations in application data testing and to analyze data in business intelligence. The only difference is that the former has more accurate queries in the application and business intelligence uses AI/ML to predict and prescribe the business forecast.

