

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


Organizations today rely heavily on data warehouses and data lakes as a home for analytical data, but they never address data consistency and scaling issues. This has resulted in data jungles and has led end users to question the accuracy and usefulness of data. As a result, making quick, fact-based judgments for businesses becomes challenging. Siloed data warehouses and data lakes have limited real-time data streaming capabilities, impacting organizations' scalability and democratization goals.
Businesses need to identify the shortcomings in their current architecture to mitigate these challenges. This blog will discuss a new approach to data architecture called Data Mesh, but first, let's look at some challenges these centralized data platforms face.
Challenges of centralized data platforms
Difficulty in scaling new data sources and data consumers
Centralizing entire enterprise data into one data warehouse affects the ability to process massive amounts of data from various sources. Importing data from edge locations to a data lake and querying it for analytics is a costly and time-consuming task. The scaling of new data sources and data consumers becomes challenging as it affects the organization's overall data model, which can greatly impact downstream systems.
A centralized team becomes a bottleneck
Due to the centralization of data in one place and datasets being managed by a central data team only, it becomes overwhelming for them. As a result, the members of this data team frequently find themselves in a tight spot and are slow in responding to changes. They spend a lot of time resolving issues introduced by data-producing teams while also dealing with frustration from data-consuming stakeholders. It is common to see them in stressful situations resulting in decreased productivity.
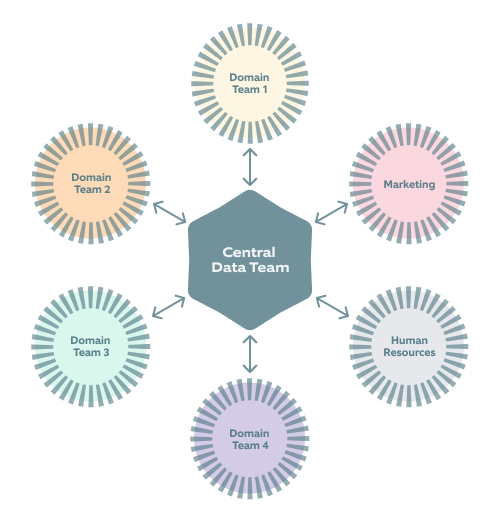 Central Data team becoming a bottleneck
Central Data team becoming a bottleneck
Lack of domain knowledge resulting in data quality issues or data inconsistency
The centralized data platform team normally works across domains because they lack knowledge of each domain and a thorough understanding of business. This creates inefficiencies in managing data which leads to data quality issues.
Ambiguous ownership and responsibility of data sources
In a centralized architecture, three roles are involved:
- Data Producers: They know everything about the data being generated and can change its shape.
- Data consumers: They understand the enterprise's business problems and make intelligent decisions to solve them based on insights obtained from analytics data.
- Central Data Team: This team oversees delivering highly curated data. Nonetheless, the members lack domain expertise and a thorough understanding of the business issues addressed by consumers.
Centralized data architecture results in a disconnect between data consumers and data producers as the latter may not be aware of how their data is being utilized across the organization. This current paradigm of ambiguous ownership and responsibility of data sources creates a bottleneck, resulting in delayed consumer insights.
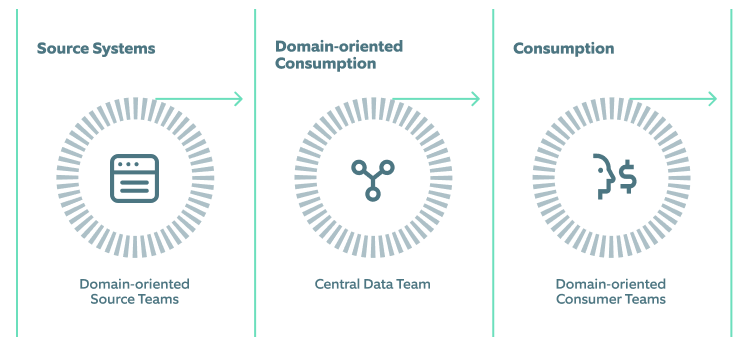
Disconnect between Data Producers and Data Consumers Team
Inefficiency in availability and accessibility of data
In centralized data architecture, the enterprise data is stored at one location, and organizations anticipate that users throughout the organization can access it. However, just because something is accessible doesn't imply that it isn't hidden behind the complicated web of data warehouses or data lakes.
Organizations facing these challenges should address them by analyzing the benefits of a decentralized architecture. A new architecture known as Data Mesh is causing quite a stir these days. Let's find out what Data Mesh is.
What is Data Mesh?
Data mesh is an architectural approach to analytical data management based on a modern, distributed architecture. It is not a technical shift but rather an organizational, architectural paradigm. It allows end users to easily access and query data where it resides, rather than having first to transport it to a data lake or data warehouse. It promotes the transition from the monolithic layered architecture represented by data warehouses or data lakes to a decentralized, distributed, domain-driven, and self-service architecture where data is treated as a first-class product.
The data mesh strategy distributes data ownership to teams that are specialized in specific domains and manage the data as a product.
Principles of Data Mesh
Data mesh architecture is based on four major principles:
Domain ownership
The Domain Ownership principle is a fundamental pillar of data mesh. According to this principle, domain teams should own their analytical and operational data in a domain-driven distributed architecture, not any central data team. This is referred to as 'domain-driven ownership of data.
Domain-oriented data product (data as a product)
The data as a product principle addresses issues of data quality and data silos, making data held by one domain group inaccessible to others within the same organization (there are consumers for data beyond the domain). Domain teams oversee delivering high-quality data to other domains. Data is delivered as a product using different data consumption methods.
Self-Serve Data Infrastructure as a Platform
Building, deploying, accessing, and monitoring data-as-a-product necessitates extensive infrastructure and expertise. This is where the self-service data infrastructure as a platform principle comes into play. A self-service data platform that follows organizational policies includes tools that can support a developer's workflow with minimal specialized knowledge and skill. Simultaneously, it must be capable of lowering the cost of developing data products.
Federated Computational Governance
Some rules and decision models are applied to data products to ensure interoperability. Domain datasets must establish Service Level Objectives for the data quality, timeliness, error rates, etc. This governance model gives a federation of data domain and platform product owners decision-making autonomy while adhering to certain globalized rules. This, in turn, results in a healthy interoperability ecosystem.
Data mesh weaves these four threads together to create a new architectural paradigm that enables large-scale data analytics. Organizations can use Data Mesh to connect distributed data sets and enable multiple domains to host, access, and share datasets in a user-friendly manner.
Why use Data Mesh
To meet business intelligence requirements, most organizations have relied on single data warehouses or data lakes as part of their data infrastructure. Such solutions are deployed, managed, and maintained by a small group of specialists frequently burdened by massive technical debts. As a result, an overloaded data team is struggling to meet growing business demands, there is a disconnect between data producers and users, and data consumers are growing impatient.
In contrast, by enabling greater flexibility and autonomy in data ownership, the Data Mesh can address all the shortcomings of data lakes or data warehouses. Because the burden is transferred from the hands of a select few experts, there is more room for data experimentation and innovation.
As a platform, self-service infrastructure enables a far more widespread yet automated framework for data standardization and gathering and sharing.
Data mesh promotes data product thinking in which datasets are considered first-class products and are the responsibility of specific domain teams instead of the central data team. That improves the data quality and fast delivery to stakeholders and addresses the issue of age-old data silos simultaneously.
"Things work better when you focus on the product and its needs, rather than the organization of its equipment."
— James P Womack, Daniel T Jones, Lean Thinking.
Data Mesh Implementation
Switching an organization to a data mesh cannot be done overnight; it must be done gradually. Management commitment is a necessary first step toward achieving business-wide buy-in. Once you have that, you can delegate responsibility to a few forward-thinking teams to produce their data as a product. This paves the way for other teams and provides valuable learnings about building data products while considering your customers' needs and laying the groundwork for federated governance.
A data product is frequently associated with a dataset containing one or more business entities, such as a customer, asset, supplier, order, credit card, campaign, and so on, that data consumers want to access for analytical and operational workloads. Consequently, a data product includes everything a data consumer requires to derive value from the data of a business entity.
Domain data products should have the following basic attributes to deliver the best user experience for users:
Discoverable
A data product must be easy to find. A common implementation is to maintain a registry, or data catalog, of all available data products, complete with metadata such as owners, origin, lineage, sample datasets, etc. Each domain data product must be enrolled with this centralized data catalog for easy discovery.
Addressable
Once discovered, a data product should have a unique address that adheres to a global convention, allowing its users to access it programmatically. Organizations may use various naming conventions for their data based on the underlying storage and format.
Interoperable
One of the major concerns in a decentralized domain data architecture is the ability to interact with data across domains. Strategies and communication guidelines should be well defined to enable organization-wide interoperability of products in accordance with customer demands.
Trustworthy and truthful
Data products should provide high data quality and accuracy to consumers by maintaining response times, performance, and availability. Data product owners must provide a valid Service Level Objective primarily focused on the data's integrity and how accurately it reflects the facts of the events that have taken place or the high probability of the validity and reliability of the knowledge and insight that have been generated.
Self-describing
Quality products do not necessitate consumer assistance. Product information should be available to explain how the product works, its features, input and output ports, SLAs, security, and so on.
Secure
Secure access to product datasets is required regardless of whether the architecture is centralized or not. In the decentralized domain-oriented data architecture, access control is applied at a higher specification for each domain data product. A simple way to implement product dataset access control is to use the Enterprise Identity Management system (SSO) and Role Based Access Control policy definition.
While your data mesh may not appear immediately, if you make purposeful changes based on its principles, you will eventually recognize its presence in your organization and begin reaping its benefits.
Below figure shows a transition from a monolithic layered architecture to a distributed architecture of data mesh:
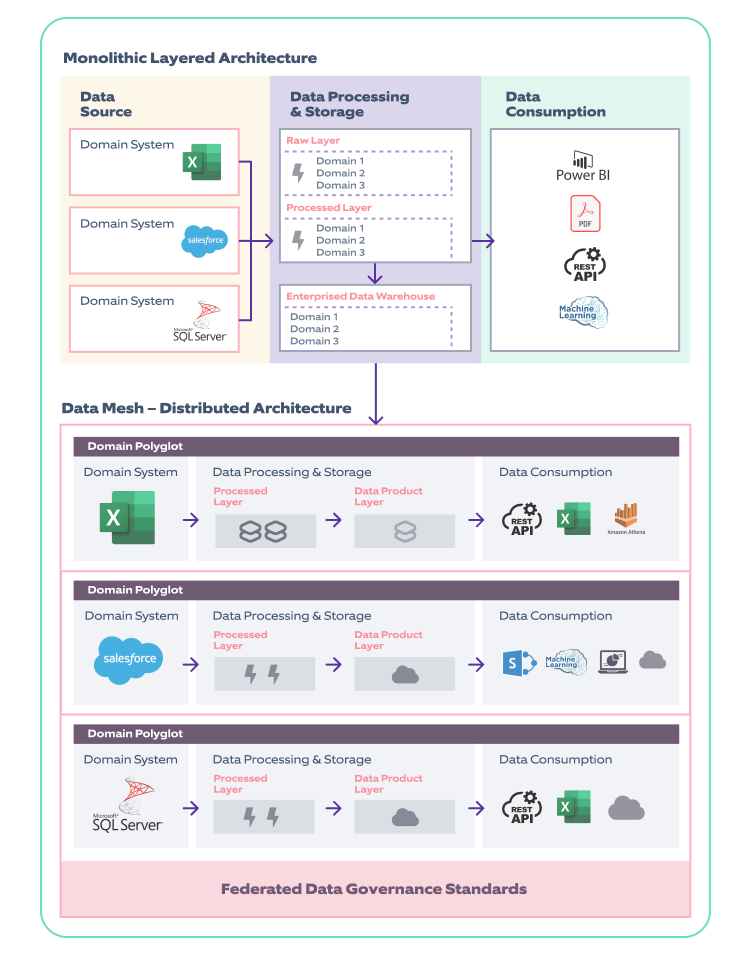
Nagarro has helped multiple customers of different industries in transforming their organization's monolithic architecture into domain-driven distributed architecture along with the creation of an adoption framework for this organizational shift.
Challenges Of Data Mesh Implementation
The complexities inherent in managing various data products (and their dependencies) across multiple independent domains are the primary challenges of a data mesh.
Data duplication across domains
Redundancy, which can occur when data from one domain is reprocessed to meet the needs of another domain, can have an impact on resource utilization and data management costs.
Quality assurance and federated data governance
When data products and pipelines are used as commodities across domains, different governance and quality requirements must be considered. As a result of this process, deltas must be outlined and federated by performing checks effectively.
Cost and risk
Existing data and analytics tools must be modified and enhanced to support a data mesh architecture. Developing a data management infrastructure to support a data mesh, which includes data integration, virtualization, preparation, data masking, data governance, orchestration, cataloging, and distribution, can be a huge, costly, and risky undertaking.
Integration
It is challenging to develop an organizational culture that strongly integrates and shares data that is owned by various teams and makes it available to authorized users.
Self-Serve infrastructure creation
Building self-service infrastructure necessitates a high level of expertise and effort to automate processes to spin resources.
Should You Mesh Your Data?
Given the numerous advantages, any organization would be wise to use the data mesh architecture for data management. Is it, however, the ideal fit for you?
One simple way to find out is to understand your current analytical requirements based on data quality, the number of data domains, the size of data teams, bottlenecks in data engineering, and data governance practices.
The higher the numbers, the more complex your data infrastructure requirements are and, as a result, the greater the need for a data mesh.
Nagarro's point of view on who should mesh their data and who should not:
| Mesh your data if: | Data mesh may not be for you if: |
|
|
Reach out to our data experts to find out if data mesh would be helpful for your organization and how it can add value to your business.
Conclusion
As businesses collect, store, and analyze more data, the notion of decentralized data ownership becomes evident. Ultimately, putting data back into the hands of those who understand is the way to go. Developing a distributed self-service architecture with centralized governance necessitates ongoing dedication.
Transitioning from a monolithic to a distributed model necessitates enterprise reorganization and cultural shifts. However, the effort is worthwhile because this transformative paradigm has the potential to boost an enterprise's data-centric vision.


