

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


A data lake is a raw storage used for storing large volumes of structured and unstructured data. A data lake is often used to collect raw data in the native format before datasets are used for analytics purposes.
"Data Lake as a Service" provides a prebuilt cloud service that hides the complexity of the underlying platform and infrastructure layers. The platform enables anyone in the organization/business to create his/her data lake without the requirement of installing or maintaining the technology themselves and can leverage the advantages of data analytics. Data Lake as a Service provides enterprise big data processing in the cloud for faster and efficient business outcomes in a cost-effective way.
Why do we need it?
In today’s data-driven world, every enterprise wants to leverage the benefits of analytics for better decision making and business growth. Every enterprise consists of multiple departments, and every department has different needs corresponding to the data. They want their data in a separate data lake or data warehouse where it can be analyzed according to the requirements to make business-related decisions. Enterprises also want to generate the billing corresponding to a particular request from the department according to the usage of environment provisioned.
Where it fits?
This requirement fits very well in the enterprises which have multiple departments or companies which want access to tools and data. Individual departments/companies want their data scientists and analysts to play with the data while making critical business decisions to fuel business growth. The focus of Data Lake as a Service is to define enterprise-wide reporting strategy to create agility and scalability.
What are the challenges?
The challenges while creating separate on-demand data lakes for various departments are:
- Automated environment provisioning
- Configuration management
- Data security management
- Data governance
- Data encryption
- Data generation based on different analytics requirements
- Billing management as per environment usage by department per request
What is the solution?
"Data Lake as a Service" provides a self-service portal where all the users have access to the organizational data according to their roles in the organization and policies. Users can request the data in their private space, i.e., their data lake environment where they can change and analyze the data as required. The users will be billed corresponding to the time and usage of the environment. The environment will be provisioned automatically on request approval, and only the users who have requested will have complete control over the environment. The environment can be de-provisioned automatically on completion of their request. Complete data security, encryption, and masking will be there as per organizational policies so that no data is compromised.
As shown below in the diagram, different teams can have different workspaces according to their requirements.
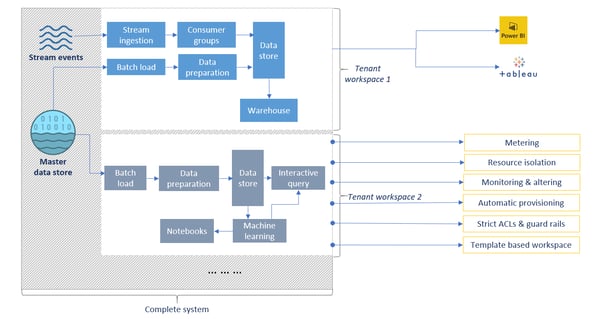 Multi-tenancy – isolation across different teams
Multi-tenancy – isolation across different teams
Also, there will be automation at every step. The self-service portal will appear as shown in the diagram below. The requested environments will be auto-provisioned, and different users will interact according to their roles in the organization.
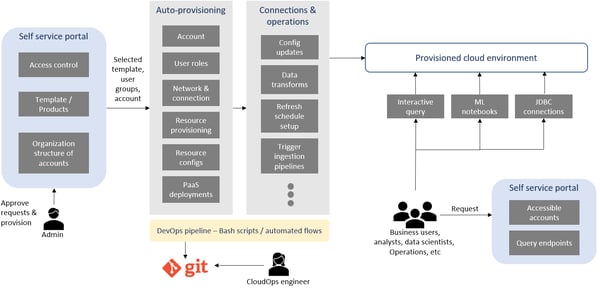 Self-service portal – automation at every step
Self-service portal – automation at every step
This self-service portal comprising all the requirements can be easily developed on Google Cloud Platform (GCP). GCP provides a wide range of services, using which we can build this platform with minimal efforts.
The self-service portal can be built using the following GCP services as shown in the diagram below:
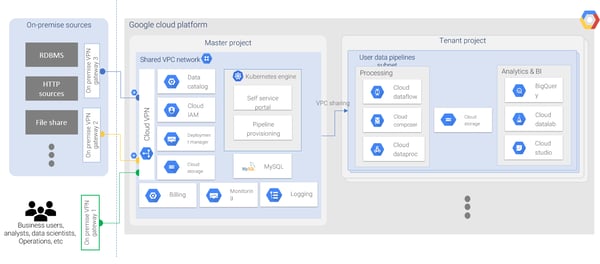
The main benefits that we get using GCP are:
- Data Warehouse: GCP provides BigQuery as data warehouse solution. BigQuery is a serverless column store warehouse with partitioning and clustering. We pay only for what we use, with optimized storage resulting in a smaller query footprint. We can easily create authorized views for row and column level access control.
- Machine Learning: GCP provides various machine learning services that can enable data scientists and analysts to use these services without putting extra efforts. BigQuery ML enables users to create machine learning models with SQL like queries. AutoML allows developers to train exceptional models specialized to their business requirements.
- Security & Governance: We can efficiently manage sensitive data with redaction services enabling classification, masking, secure hashing, tokenization, bucketing, and format-preserving encryption. GCP provides granular billing based on user and resources with per-user-per-resource quotas available.
- Automation: GCP provides deployment manager for provisioning environments using APIs and templates, without any human interference. Deployment manager uses a declarative approach that enables the user to establish the configurations and allows the system to assess the steps to take to create the resources.
Using GCP and its services, we can easily remove the challenges that we discussed earlier and build a system with minimal cost and efforts.
The benefits of Data Lake as a Service:
- Automated environment provisioning per request
- Data security & governance
- Full control over data
- Cost management per request/environment
- Multi-tenant data architecture
- Integrate and expand current enterprise data warehouse (EDW)
- Scale as per requirements
- Self-service analytics and visualization platform
- Isolation at the team level
We@Nagarro offer “Data Lake as a Service” as an accelerator to many customers. We organize workshops with customers to discuss their requirements in detail, share our experiences, brainstorm over the challenges, business use cases, and deliver this within a few weeks of effort. Also, this solution is not only limited to GCP, but Data Lake as a Service can also be very well implemented with other cloud providers like AWS, Azure, etc.

