

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


Since the dawn of electronic computers, the distribution of computing resources has ebbed and flowed between centralized and distributed locations. Early computers were centralized due to cost and complexity. As computers grew more compact and communication technology developed, it became possible to connect to a centralized mainframe from a distance via a terminal. Eventually, personal computing was born, making it possible to perform certain classes of computing just about anywhere with a source of electrical power. At this point, computing split between intensive workloads requiring a mainframe and lighter workloads requiring only a personal computer.
With the advent of the internet, general demand for centralized services arose to complement what was possible on a personal computer. Servers across locations and data centers provided various services and websites. To make these services easier to manage, cloud computing arose, creating centralized data centers to improve scalability and lower maintenance costs. At the same time, personal computing devices grew more mobile and numerous, and large numbers of embedded systems developed connectivity and reliance on centralized services, forming the internet of things (IoT).
Now we arrive at the current state of affairs. The most prevalent manifestation of computing consists of various types of individual computers relying on centralized services, which arrangement largely serve users’ needs but comes with challenges.
The problem
Most devices at the edge—as we call the entry point to the network, where data is produced—are physically distant from the servers, cloud or otherwise. This creates two major liabilities:
- Non-negligible latency, which hampers real-time applications
- Long-distance data transfer, which, in high-data-volume applications, increases network traffic and cost while reducing performance
These are real challenges in applications requiring immediate response to user actions or fast processing of large data volumes.
A solution
One way to resolve these problems is to further distribute computing normally performed in the cloud to locations close to the edge. Compute and storage resources are strategically distributed throughout the network where they are needed by devices connected to the network. This distribution could be viewed as a spectrum of computing power against distance from centralized cloud services. The most powerful and general compute resources remain centralized. At the same time, lower-power or more specialized devices are placed between the cloud and the edge or, in some cases, at the edge.
For example, regional cloud resources might use high-powered servers for the heaviest workloads that are not time-sensitive. Servers of somewhat lower power (sometimes called cloudlets) might be placed in locations serving individual cities or counties. These would still be generalized compute, but latency would be reduced as the distance to end devices would be smaller. A third layer of computing might be used in specific buildings within a LAN for specialized applications, such as video processing or building management. This third layer would be more specialized and tailored to the application, handling machine learning models or filtering sensor data. A final layer might exist in some applications, with specialized services provided only a single hop from end devices, such as in a plant or container ship. To further round out the cloud-edge processing spectrum, end devices might have enough horsepower to handle some of their own processing, such as specialized machine learning processors or FPGAs (field-programmable gate arrays).
The advantage of this arrangement is that purpose-designed devices efficiently provide the most specialized, time-sensitive, and data-intensive services. Less time-sensitive workloads can be strategically placed at a distance that will optimize response time against bandwidth and cost. This can help reduce latency from tens or hundreds of milliseconds to as low as a few milliseconds. And limit high volume data transfer to much smaller network distances and, in some cases, even confine it to a LAN.
In this arrangement:
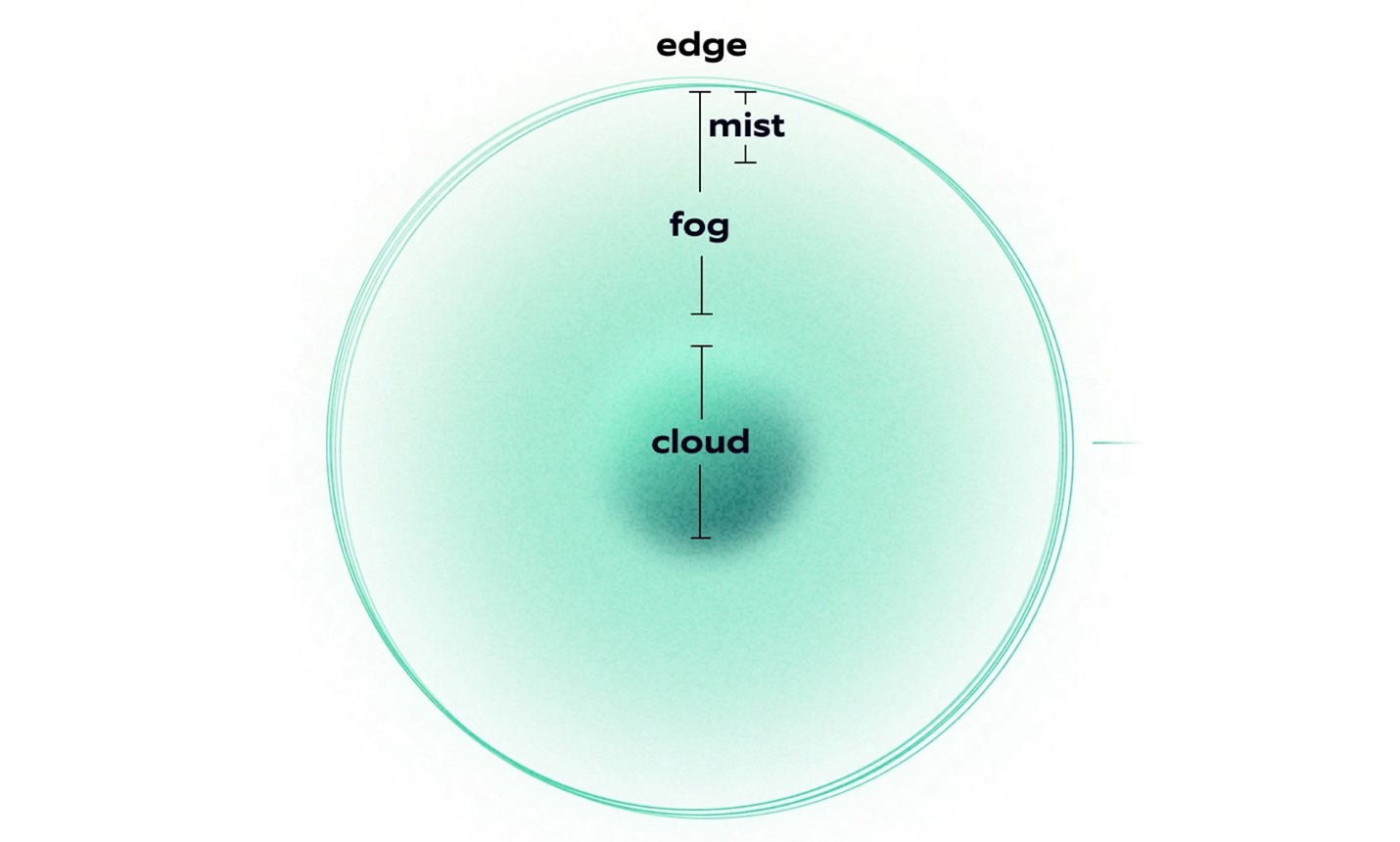
- cloud is the most centralized, regional computing infrastructure;
- fog (a cloud close to the ground) is computing infrastructure somewhere between the cloud and the edge; and
- mist (a light fog) is lower-power or specialized compute closer to the edge.
Edge computing generally refers to computing resources at or relatively close to the edge and encompasses mist and fog computing to some degree. The intelligent edge refers to services at the edge that would normally require significant processing power but can now be handled by specialized devices. These terms are still in flux and may have slightly different definitions depending on who uses them. The definitions are taken from NIST Special Publication 500-325, Fog Computing Conceptual Model.
Applications
Let's get down to brass tacks. Where is edge computing useful? A few notable use cases are:
Peer-to-peer interaction
In real-time applications, such as gaming or communication, or shared interactive experiences, the lag induced by long-distance data transfer (required for centralized processing) can easily ruin the experience. In these applications, performing critical processing near the edge when common participants are in a shared location can help reduce latency and increase responsiveness.
Augmented and virtual reality
Both AR and VR require immediate processing of large data volumes with imperceptible response times. Providing the required services centrally would produce noticeable lag. In these applications, carrying out some data processing on the AR/VR device itself can be helpful, ensuring critical shared services are as close to the edge as possible.
Video processing
Video tends to produce large volumes of data. Various video applications may not require video data to be processed or stored centrally. Surveillance systems might be set up to look for specific triggers and record only a small subset of the footage. These triggers can be processed at the edge or in the fog to minimize data transfer. Other video applications may only be interested in features extracted via machine learning. In such cases, the ML models can be run near the edge with only the relevant features transmitted for central storage.
Transportation and logistics
Ships, trains, aircraft, trucks, and other vehicles must be tracked, along with their goods. This can require many individual tracking devices in a single shipment, producing various types of sensor data with no or unreliable connectivity. In these applications, central coordination systems that travel with the sensors are critical for management, cost, and reliability.
Industrial monitoring and control
Shared monitoring and control can be performed near the edge for improved efficiency in some industrial systems. In contrast, central computing is used for common data storage and time-insensitive configuration and control. In systems with sensitive control feedback loops, delay (latency) is critical and cannot be performed far from the system under control. And complex systems of sensors can produce large volumes of data, much of which can be discarded after analysis close to the edge.
Safety-critical systems
Medical devices and automotive and aviation systems are subject to rigorous safety requirements and cannot withstand the unreliability of typical network connections. While these systems are often self-contained to limit exposure, some applications may benefit from shared services for data processing or central coordination and control. Keeping these shared services local to the end devices over robust communication links is critical.
Robotics
Cloud systems cannot handle coordinated robotics systems requiring central control due to high, unpredictable latency. These distributed systems are inherently tightly coupled. Shared services may be distributed amongst the coordinated devices and shared servers near the edge, with time-insensitive services or control offloaded to the cloud.
Adaptive caching
A CDN (content delivery network) locates its caches near the edges of the network to improve data availability and response time. Similarly, local caches can be set up to make predicted or requested data available with minimal lag and network traffic.
Advantages of edge computing
Many of edge computing’s advantages should be clear by now—let's enumerate them:
- Latency – Reduced network distances reduce data transfer latency, increasing responsiveness.
- Network traffic – Local services limit the need for data transfer across the network, reducing network traffic and data movement cost.
- Context-awareness – Since edge services are limited in scope, they can make assumptions about their environment—location, clients, network characteristics, etc.—that add to environmental awareness and improve service quality.
- Efficiency – Edge computing can be surgically tailored to the application, allowing the use of specialized devices and optimized connectivity for energy, communication, and cost-efficiency. Further, data processing near the edge can reduce data storage requirements.
- Availability and resiliency – A well-designed edge architecture reduces the risk of service failures. As services are divided and distributed throughout the fog and edge, the loss of a single service provider produces only localized outages. Fallback services can mitigate these outages, either at the same layer or further from the edge. Such resiliency requires careful design and implementation.
- Data ownership – A major concern in gathering personal data is ensuring privacy and minimizing data collection and storage. Edge processing encourages a system design that is inherently careful about information storage.
Considerations and challenges
Edge computing is no panacea. It requires careful design and management to avoid devolving into an unmanageable mess. Centralized systems often have the advantage that they require simpler management mechanisms. Distributed cloud computing increases complexity, but still uses relatively homogeneous resources, mostly connected via predictable links. Fog, mist, and edge computing may consist of widely varying compute resources in wildly different locations using the entire spectrum of connectivity mechanisms, many of which may be highly unreliable. Management and orchestration systems must handle this heterogeneity, and architecture must account for it.
The architecture of such diffuse systems is a more extensive subject, but some of the primary considerations include the following.
Location
Where to place edge compute infrastructure is a primary question. Place resources too far from the edge and latency requirements cannot be met, and network congestion may become a problem. Placing resources too close to the edge, however, means more infrastructure is required, raising cost and management complexity. These factors should be balanced for optimal efficiency.
One approach is to make use of managed edge services of various types. For example:
- AWS Local Zones extends standard AWS infrastructure to large cities for fog resources.
- AWS Outposts similarly allow ad hoc deployment of AWS infrastructure when required for immediate network placement.
These resources are called cloudlets, or cloud infrastructure brought close to the edge. Another service type that utilizes cellular infrastructure is multi-access edge computing (MEC), which uses compute resources deployed at cell sites for immediate access by cellular subscribers. Some relevant managed services are:
- Verizon 5G Edge and AWS Wavelength provide managed MEC services.
- Google similarly offers a range of edge deployment options under the name Google Distributed Cloud Edge, and Azure provides a similar set of offerings under the names Azure IoT Edge and Azure Private MEC.
Device selection
End devices may be anything from low-power microcontrollers to mobile phones or powerful gaming hardware. The types of hardware that serve these end devices in the fog or at the edge are dependent on the required services and scalability. General compute resources—such as cloudlets—may be deployed, but specialized hardware exists for specific workloads to improve efficiency. Some examples:
- NPUs (neural processing units), TPUs (tensor processing units), and other AI accelerators exist to handle machine learning algorithms efficiently.
- DPUs (data processing units) are specialized devices that handle algorithms run in high-throughput applications.
- SoCs (systems-on-chip) and related devices, such as SOMs (systems-on-module), efficiently combine heterogeneous functionality into a single package to handle varied workloads.
- FPGAs (field-programmable gate arrays) can be used to efficiently provide specialized compute for applications where general computing is inadequate and ASSPs (application-specific standard products) do not exist. Though FPGAs are not generally known for their low power consumption, more recent models have been approaching the characteristics of low-power devices such as microcontrollers. And for very high-volume applications, ASICs (application-specific integrated circuits) can be developed and are becoming easier to design and manufacture.
Power consumption of end devices is often critical, but the power characteristics of edge compute can likewise be important, depending on where the hardware is deployed. Defining a power budget and choosing devices that meet those requirements while providing the required horsepower can be a tricky balancing act.
Orchestration and monitoring
One of the major difficulties of diffuse infrastructure is resource management. Deploying, cataloging, monitoring, and maintaining resources becomes unmanageable at scale, especially when heterogeneous and geographically distributed. The use of well-designed platforms tailored to the orchestration and monitoring of edge resources is critical. Several such platforms exist on the market as managed solutions.
Service discovery
Another problem in diffuse systems, particularly in edge computing, where highly location-dependent services are deployed, is service discovery. The process of determining which network resources to call for a particular service must consult the location and nature of the requestor. While a central API for service discovery could serve the purpose, it would reduce the efficiency provided by edge architecture and thus partially defeat its purpose. A better approach is to use distributed, context-aware DNS to resolve host names and service requests to the most local available network resources with fallbacks for resiliency.
Security
In the CIA triad of information security (confidentiality, integrity, availability), edge computing, when well designed, can increase integrity and availability by making the system more dispersed and resilient. In the case of confidentiality, however, diffuse, heterogeneous infrastructure increases the size of the attack surface and considerably complicates security. There is no turnkey solution for edge security—or any network security, for that matter. But a careful approach to system architecture and service implementation, with a robust platform for maintaining and monitoring infrastructure, is a good start. Rapid roll-out of firmware and software updates and security fixes prevents exploitation of out-of-date resources, while comprehensive observability allows rapid detection of and response to security breaches, along with isolation of compromised resources.
On the brink
The rapid proliferation of devices—such as IoT and mobile devices—requiring real-time services or producing large amounts of data presents significant engineering challenges that cannot be fully resolved using cloud computing. Fog, mist, and edge computing offer an approach that—while not without its challenges—holds great potential as a solution. As time goes on and such applications become more prevalent and demanding, we will increasingly see a shift from centralized cloud computing to edge computing.
-2.png)
