

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


George is a software engineer at a company that supports healthcare providers with patients' medical records on their mobiles to enable smarter care. With so many physicians and patients relying on the system, users can ill-afford any outages. Recently, the application had an outage, hampering communication between doctors and patients as electronic health records containing patient medical histories were unavailable. It affected tens of thousands of users, all facilities and ambulatory care sites, and cost them several hours of operation.
Food for thought: What could they have done differently to prevent the sudden outage?
Bring chaos to the calm. Does that seem as irrational or absurd as it sounds? Well, it's not.
What is chaos engineering?
A term introduced by Netflix, chaos engineering is about finding weaknesses in a system through controlled experiments. It helps identify and fix failure modes before they can cause any real damage to the system. Contrary to what such a name might imply, chaos engineering events are planned, and service disruptions are thoughtfully scheduled to assess:
- whether the system can cope up with a disruption
- how user experience may get impacted
- if the response protocols and alerts are working efficiently
It is an evolution of software testing applied to production.
While the primary adopters of chaos engineering were eCommerce and IT giants such as Amazon, Microsoft, and Google, it has become imperative for businesses of all shapes and sizes. Here's why (if you wonder): Today, customers have high expectations and less patience. If your application is unresponsive, they will switch to your competitor. You would not want that to happen, would you?
Why and when should you consider chaos engineering?
Break your systems productively.
As per Gremlin's State of Chaos Engineering 2021 report, teams that frequently run chaos engineering experiments:
- have more than 99.9% availability
- 23% of respondents had Mean Time to Repair (MTTR) of under 1 hour
- 60% of respondents' MTTR was under 12 hours
A critical metric, MTTR helps measure the time required to troubleshoot and fix a failed system.
MTTR makes chaos engineering critical as it helps pre-empt and prepare for a disaster that could cost millions. It expedites identifying and addressing issues proactively before they reach your users.
In other words, chaos engineering helps you get answers to questions such as:
- What happens when a service is not accessible?
- What if the application goes down after getting too much traffic?
- Will we experience cascading failures when a single service fails?
- How does the application deal with network issues such as network latency or packet loss?
Who needs chaos engineering?
Who doesn't?
If you think chaos engineering is just for IT organizations, you are mistaken! From eCommerce, healthcare, and finance to manufacturing, aviation, and beyond, chaos engineering has a foothold across industries. After all, which industry would be willing to risk a service disruption that could potentially cost them millions of dollars due to an avoidable glitch?
Case in point: An online trading platform used by millions of customers at a time requires high availability, security, robustness, and resiliency. One sudden outage means chaos – preventing users from accessing their accounts, hampering trades, and leading to significant legal and financial implications.
Another recent example is an outage at some Amazon Web Services cloud servers that wreaked havoc on 8th December 2021. Several services, including video streaming service Netflix and Disney+, trading app Robinhood Markets Inc, online games PUBG and League of Legends, and Amazon's eCommerce site, Kindle, Amazon Music – all came to a grinding halt. This shows how services have become interconnected, and a server outage can have a rippling effect.
Any service that depends on the software that provides digital convenience requires chaos engineering to control any chaos in their environment. Chaos experiments are planned processes to induce harm into a system and learn how it responds.
A popular experiment is about stress testing IT infrastructure for load and dependencies.
- You can begin by changing the memory, disk, or CPU usage parameters.
- After that, perform testing to see how the experiment affects the system performance.
You might see that by artificially increasing CPU usage and depriving legitimate requests of computing power, users are experiencing a 15% surge in web time latency. This can further help in:
- altering configurations,
- planning for auto scale-up of resources,
- adding infrastructure to the resources supporting your system.
Another experiment can be about analyzing the cascading failures.
- Web applications may comprise several interconnected microservices.
- If one service fails, it can cause the failure of another dependent service.
- For instance, 'I run Service A, and, for it to work, I need Service B and C to work.'
- A chaos engineering experiment can place an artificial load on a secondary service and monitor the impact in this scenario.
How to get started?
Undertaking the journey from 'unknown(s)' to 'known(s).'
Chaos engineering means breaking things in a controlled environment through well-planned experiments and building confidence in your system to withstand chaotic conditions.
Here are the steps to get started:
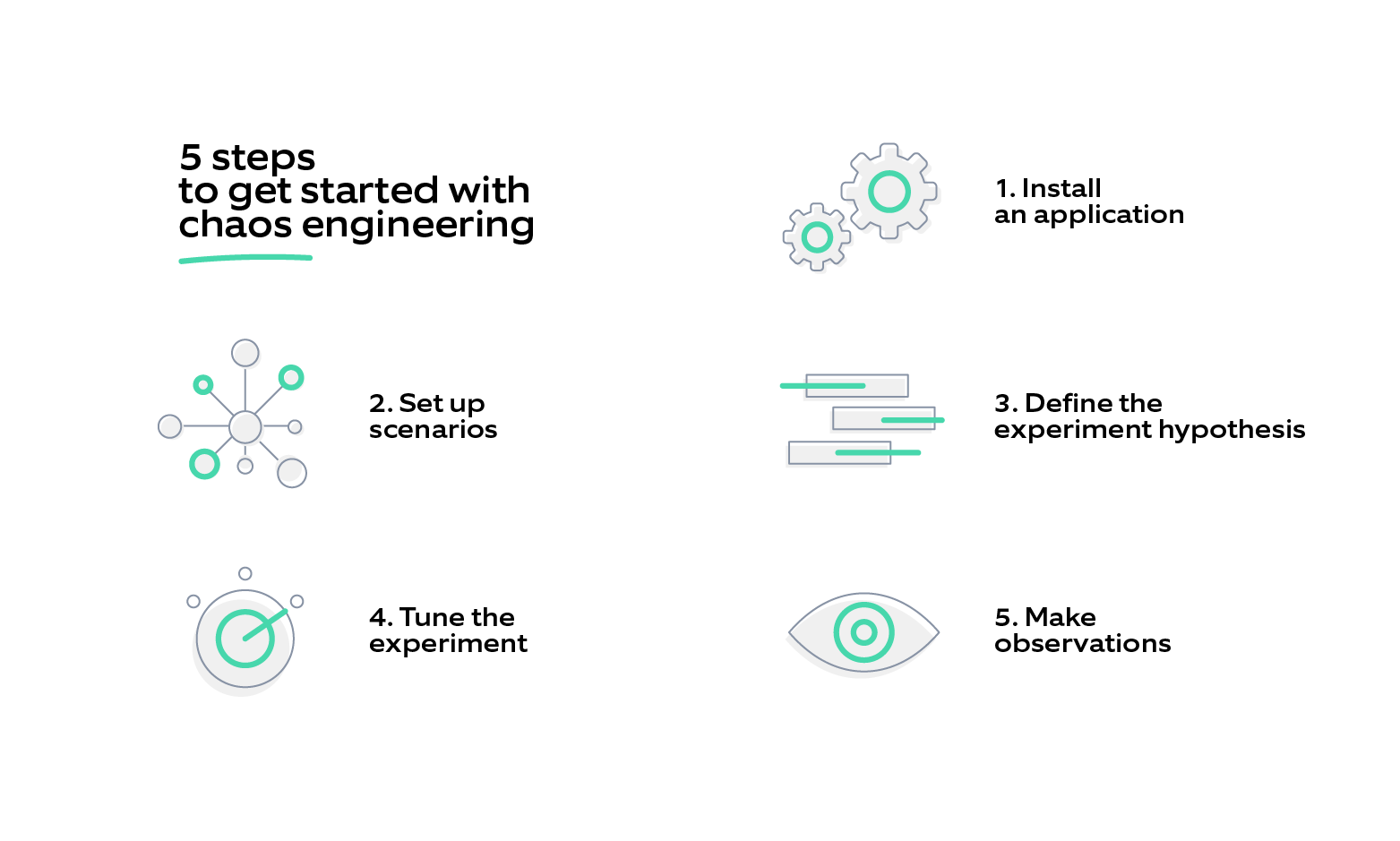 1) Install an application: There are several chaos engineering tools that can test a system's resiliency. You can configure any of them to perform experiments like resource exhaustion, DNS unavailability, black hole, etc. and gauge how the system behaves under stress.
1) Install an application: There are several chaos engineering tools that can test a system's resiliency. You can configure any of them to perform experiments like resource exhaustion, DNS unavailability, black hole, etc. and gauge how the system behaves under stress.
2) Set up scenarios: Simulate the exact failure scenarios to test the system.
3) Define the experiment hypothesis: Decide a steady-state (the good state of a system) and create a hypothesis around the failures. For instance, 'If service A experiences a node failure, it will failover within an acceptable amount of time with no impact to Service B.' Now consider the metrics you would require to evaluate the hypothesis. In this scenario, you can consider latency and error count from service B.
4) Tune the experiment: When you start the experiments, you can update the configuration for each one of them.
5) Make observations: Monitor the results closely and evaluate if your hypothesis was correct. This will help take the required steps to make your system more reliable and resilient.
Follow these steps to inject chaos right into CI/CD pipelines. We have a proven framework that enables our clients to execute chaos at scale.
Chaos engineering best practices:
.png?width=1564&name=Chaos%20engineering_%20-02%20(1).png)
- Learn about the infrastructure/applications and their dependent components
- Create Service Level Indicators (SLIs)
- Practice in a pre-production environment: Run the first chaos experiment in a non-production environment to minimize the risk. Keep the blast radius as small as possible to see how the system responds to minimal stimuli.
With experience and frequent gamedays (days dedicated to chaos), you can also practice chaos engineering in production. Focus on creating strategies that enhance resilience and build graceful degradation strategies to minimize the impact on end-user experience with minimal effort and risk.
Embedding observability
Moving from reactive monitoring to proactive observability
When outages occur and every second counts, the time spent trying to find out how and why the service/system failure can be avoided, thanks to chaos engineering. Whenever your system fails, you must know the root cause and effects. So, whenever we run chaos experiments, a robust visualization strategy plays a pivotal role in evaluating the system's performance. This helps understand a system's steady states and the changes it experiences in case of an issue.
Many monitoring and alerting systems (such as Prometheus) are widely available. It is a time-series database that stores values and provides aggregate insights from data series in real-time. The stored data must be presented in dashboards, interactive summaries, and other visualizations to ensure quick access and understanding across development teams. Supporting various data sources, tools such as Grafana can help visualize multiple metrics in a dashboard for simplified comprehension.
How Nagarro can help in your chaos engineering journey
We must be stronger than our weakest link.
Failure in a system is inevitable. Yet, 34.5% of large-scale and 40.3% of small-scale organizations have never practiced chaos engineering!
Are you amongst them too?
Nagarro's resilience engineering services can help iron out the chaos! With extensive experience and a proven chaos engineering framework, we can help:
- root out a system failure before it becomes an outage
- ensure five-nines availability, optimize your production environment
- develop a culture of resilience engineering.
Get in touch with our experts and cut out the chaos from those 3 am calls or working weekends for your team!



