

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


 AI and machine learning are revolutionizing our world. Personalized product recommendations, natural language processing and face recognition have found their way into our daily lives. In other applications, using artificial intelligence and machine learning is still in its infancy. This much is obvious for software testers: machine learning will change our view on software quality.
AI and machine learning are revolutionizing our world. Personalized product recommendations, natural language processing and face recognition have found their way into our daily lives. In other applications, using artificial intelligence and machine learning is still in its infancy. This much is obvious for software testers: machine learning will change our view on software quality.
I have consolidated a brief overview of some of the most important quality criteria, to help you get started on quality assurance for machine learning.
Of course, theories and mathematical foundations for machine learning are far more complex than taken into consideration here. Furthermore, there are several exciting developments in machine learning and AI currently. To keep things simple, this post will refer to deep learning wherever there is a determination necessary.
What is machine learning anyway?
Machine learning (especially deep learning) can help to solve problems that were difficult or impossible to solve by computation. These problems include:
- Recognizing patterns in data series and predicting future values (e.g. deducing personalised product recommendations from previous purchases).
- Clustering data-sets and assigning categories (e.g. image or facial recognition).
- Detecting deviations from normal behaviour (e.g. fault detection in operation).
To solve those problems, a model is trained and parameterised based on sets of input data. This model is used to determine the probability of different possible outcomes. The probable output is not always the same as the actual result.

Quality criteria for machine learning
As you can see from the characteristics described above: Software quality in machine learning systems is different from what we are accustomed to. Above that, the relevance of each quality criteria may vary for each system. But let’s have a look at some basic criteria to get us started.
1. Accuracy
The most important quality characteristic of a machine learning algorithm is the accuracy of the category mapping or prediction. The accuracy that can be achieved depending on the specific problem, the model, as well as the type and quantity of input data.
Of course, the objective is to have the best possible accuracy. But it may be necessary to determine a required minimum accuracy.
For example, a fraud detection system sometimes rejects valid inputs because they are rated as fraud attempt (false positive). Even if only a very few misjudgements occur, this may cause poor customer feedback. The fraud detection therefore must be highly accurate.
In contrast, poorer accuracy may suffice in a recommendation engine that displays product advertisements matching the customers’ interests.
2. Robustness
Another important quality trait is the robustness with respect to varying inputs. You must try to avoid two opposing problems: bias and overfitting.
Bias (or underfitting) occurs when a machine learning algorithm bases its decisions on too few input parameters. Additional information from other inputs is disregarded. There are some prominent examples of such bias in recent years.
Overfitting (also overtraining) occurs when irrelevant or insignificant characteristics are included in the decision-making process. Those characteristics may influence the outcome out of proportion to their real relevance.
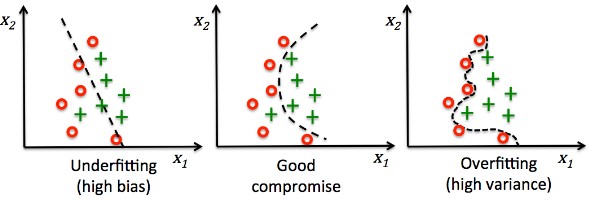
A system may require robustness against noise (irrelevant information) or it may have to cope with a high variance in the input data (e.g. faces in different angles and light conditions). However, because of the bias-variance-tradeoff it is not possible to maximize both at the same time. Knowledge about possible inputs and quality objectives are therefore essential.
3. Learning efficiency and adaptation
How many learning cycles (input data) does the system need in order to achieve accurate results? This is another quality criterion for machine learning. With each new input i.e. with each learning cycle, the system adjusts the weightage assigned to each parameter in its internal model. Depending on the model and algorithm, a system may achieve optimum accuracy with fewer or more learning cycles.
The required efficiency in learning often depends on available data for training (labelled and unlabelled). In general, even systems with low learning efficiency may achieve a high degree of accuracy if training data is abundant. Today even pre-trained models exist for some frequently required solutions, e.g. image recognition.
4. Performance
Do not forget to consider the performance of the system, i.e. the requirements in memory and computing capacity to complete pre-processing and training. Last but not least the time to calculate the actual result for each new input must meet requirements.
Exciting times lie ahead of us testers. So, to understand and determine quality requirements of machine learning systems is an important step. To verify them will be another new challenge.
Recommended reading:
- Introduction to "Deep learning": https://deeplearning4j.org/neuralnet-overview
- Dr. Rainer Kegel, Chief Information Officer of the Wiener Stadtwerke Holding AG, in an Interview on IoT and Big Data (in German)
- A SMART vision of the future (in German) by Clemens Mucker
