

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


 In today's fast-paced volatile world anything that can go wrong, will go wrong. A service interrupting event, network outage, power outage, a bug in the latest application push or sometimes even a natural disaster can catch us off-guard at any time and disrupt our business continuity. While there is no way to prevent all disasters, we can be prepared for them by formulating a robust data recovery plan.
In today's fast-paced volatile world anything that can go wrong, will go wrong. A service interrupting event, network outage, power outage, a bug in the latest application push or sometimes even a natural disaster can catch us off-guard at any time and disrupt our business continuity. While there is no way to prevent all disasters, we can be prepared for them by formulating a robust data recovery plan.
The Amazon Web Services (AWS) solution
According to Amazon Web Services ‘Disaster recovery is a continual process of analysis and improvement, as business and systems evolve. For each business service, customers need to establish an acceptable recovery point and time, and then build an appropriate DR solution.’
AWS helps customers develop a robust, cost-effective, targeted and well-tested disaster recovery plan. It all begins with business impact analysis to work out two key metrics:
- Recovery Time Objective (RTO): The maximum acceptable length of time that your application can be offline.
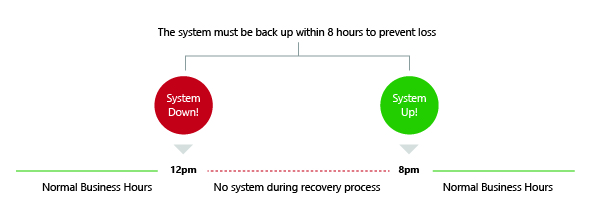
- Recovery Point Objective (RPO): The maximum acceptable length of time during which data might be lost from your application due to a major incident. This metric will vary based on the ways that the data is used. For example, frequently modified user data could have an RPO of just a few minutes, whereas less critical, infrequently modified data could have an RPO of several hours. This metric describes the length of time only and does not address the amount or quality of the data lost.
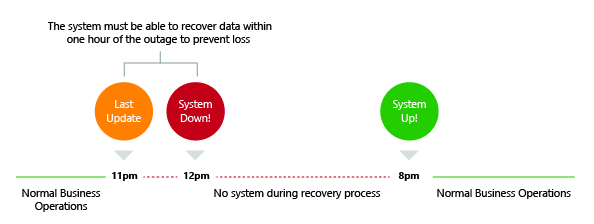
The shorter the RTO and RPO, the more your application will cost to run.
Given these metrics, AWS offers 4 basic techniques for back-up and disaster recovery.
1. Back-up and Recovery
One approach is The Cold Method, a traditional model that requires periodically backing up the systems on tape and sending them off-site. With AWS, there are several mechanisms available to achieve this and the choice would be purely based on the pre-decided RPO. Using reliable services like S3, Direct Connect and Import Export, backup solutions can be defined using the reliable network connectivity AWS provides.
The overheads of using this approach includes defining retention times, ensuring security of archives and regularly testing the backups. The RPO in this case will be huge and there will be a downtime before for restoration.
2. Pilot Light
The second potential approach is Pilot Light where the data is mirrored, the environment is scripted as a template and a minimal version of the system is always running in a different region. The idea comes from the gas heater analogy where a small flame is always on and can quickly ignite the entire furnace, when required. The core element of the system, usually the database, is always activated for data replication and for the other layers, server images are created and updated periodically.
In case of a disaster, the environment can be built out and scaled using the backed-up amazon machine images (AMIs) around the pilot light. The Pilot Light approach reduces the RTO and RPO and provides the ease of just turning on the resources – the recovery takes just a few minutes. Amazon Cloud formation can be used to automate provisioning of services.
Apart from relatively higher costs, the overheads include testing, patching and configuring the services to ensure they match the production environment.
3. Warm Standby
The next level of the Pilot Light approach is the Warm Standby. It ensures that the recovery time is reduced to almost zero by always running a scaled down version of a fully functional environment. During the recovery phase, in case the production system fails, the standby infrastructure is scaled up to be in line with the production environment and DNS records are updated to route all traffic to the new AWS environment.
Essentially a smaller version of our full production environment is being run here so this approach reduces RTO and RPO but incurs higher costs as services are running 24/7.
4. Multi-Site
As the optimum technique in backup and disaster recovery, Multi-Site duplicates the environment and there is always another environment serving live traffic running in a different region in an active-active configuration. DNS weighting is used to distribute incoming requests to both sites. Automated failover is configured to re-route traffic away from the affected site in the event of an outage. Once the primary site has been restored to a working state, we need to follow the failback process. Depending on the disaster recovery strategy, this means reversing the flow of data replication so that any updates received while the primary site was down can be replicated without loss of data.
The four techniques discussed above are not mutually exclusive and can be used in combination depending on the RPO and RTO metrics. Irrespective of the disaster recovery requirements, a well-designed and tested disaster recovery plan must ensure that the impact on a business's bottom line will be minimal when disaster hits. It has to be an amalgamation of a robust, flexible, and cost-efficient selection of strategies that can be used to build or enhance the solution that is right for the business.
